这是开始,也可能只有开始
0 课前准备
1.谷歌浏览器,这个去这里下载 2.Web Scraper , 能科学上网的直接去这里下载安装,不能科学上网的就到百度网盘
链接: https://pan.baidu.com/s/1sh7s-PZdkk-ppUFGouyzEg 提取码: 3d9h
安装的时候如果出现问题,可以查看这个
安装完成之后,能在谷歌浏览器上看到 Web Scraper
1 打开 web scraper
打开 Web Scraper 其实很简单, 按 F12 或者点击鼠标右键,然后点击检查
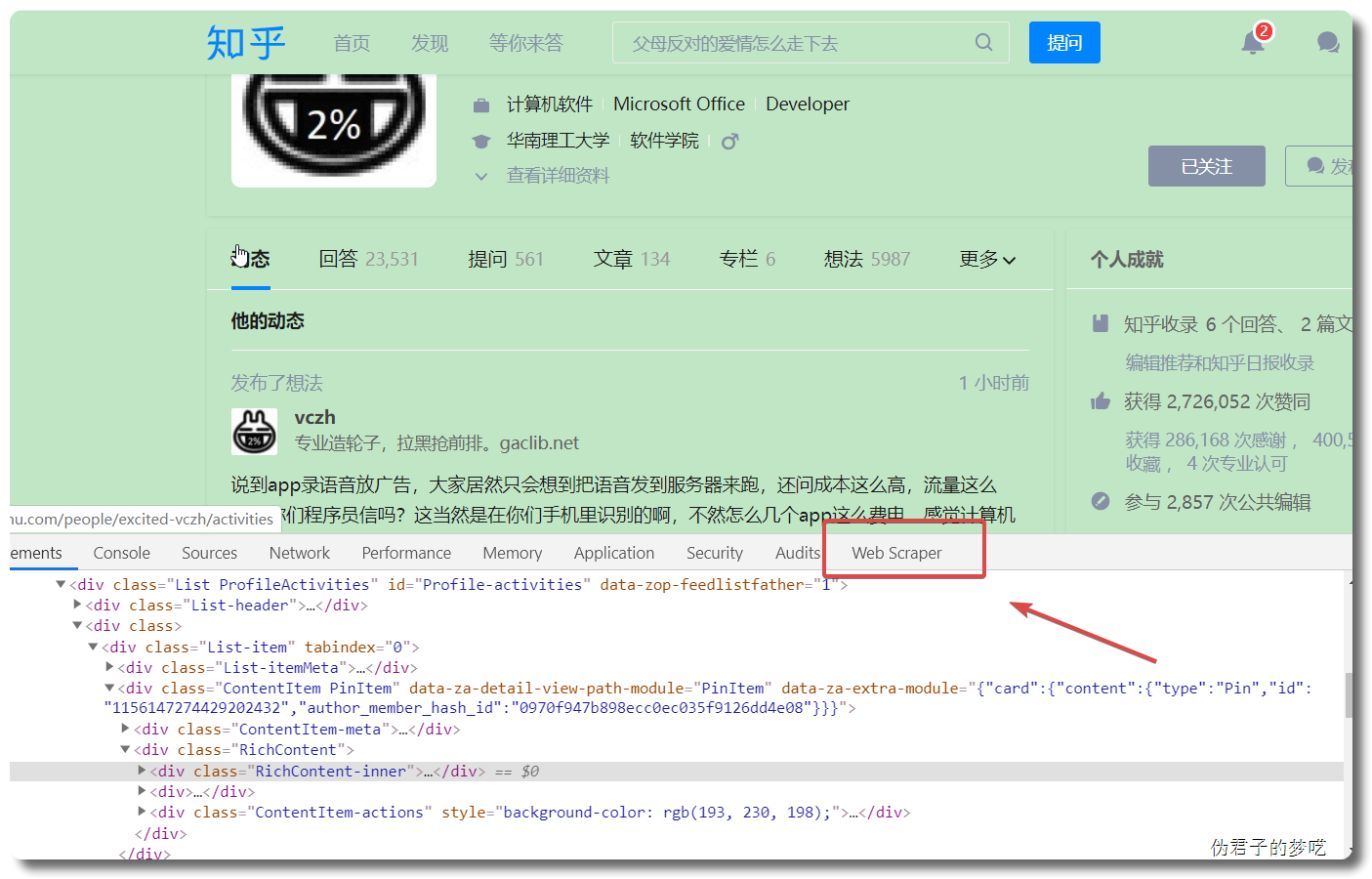
2 爬取某乎上的数据
https://www.zhihu.com/people/excited-vczh/answers
进入上面这个链接,打开web scraper
先点击 Create new sitemap,然后点击 Create Sitemap,然后会跳转到一个新的界面
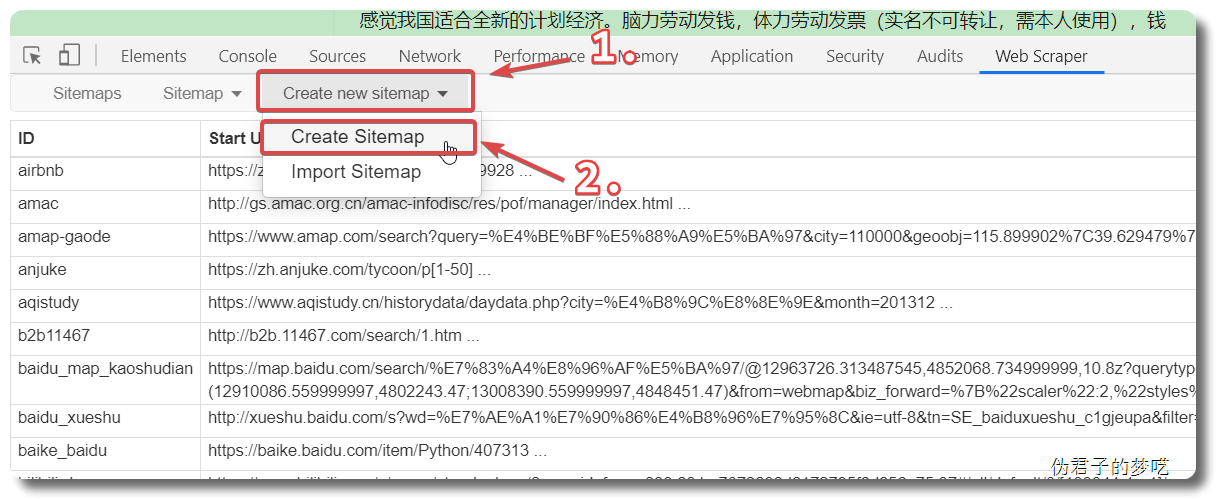
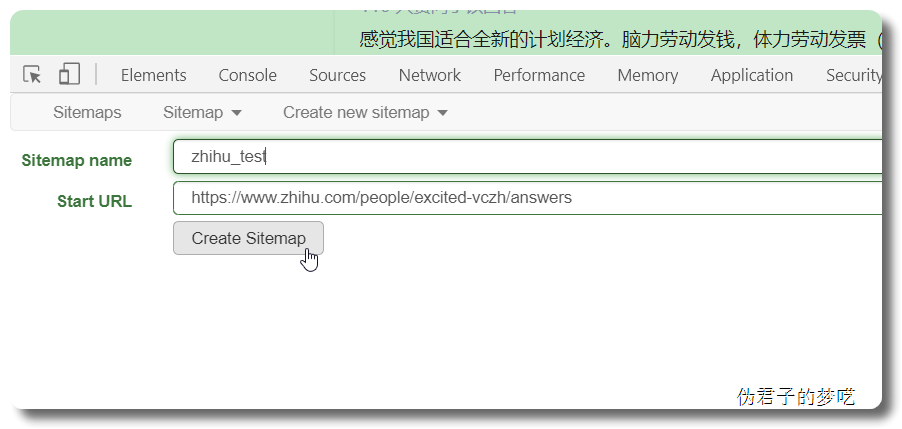
Sitemap name 填自己能记住的词,英文+数字都可以,只能用英文开头。
然后点击 Create Sitemap
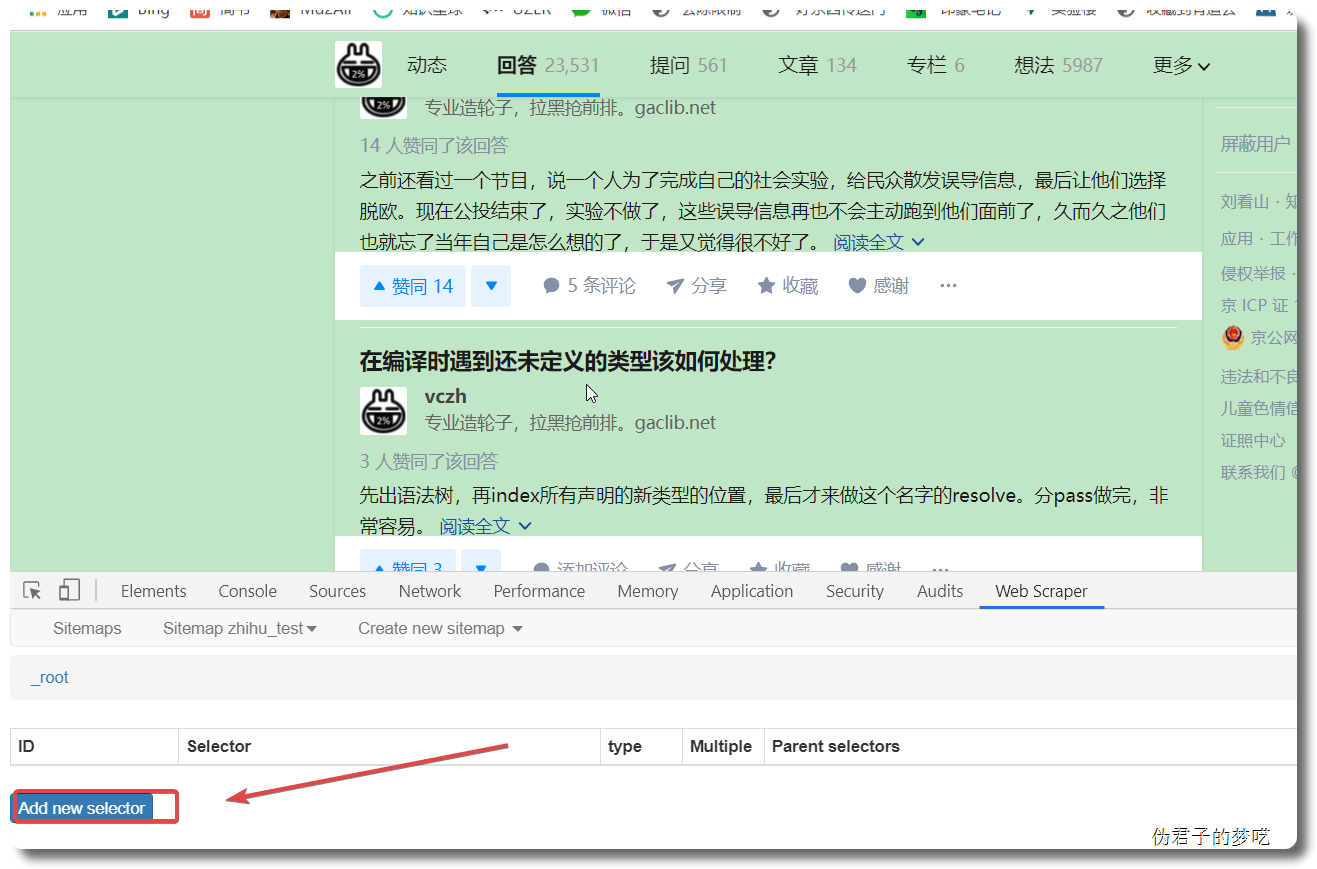
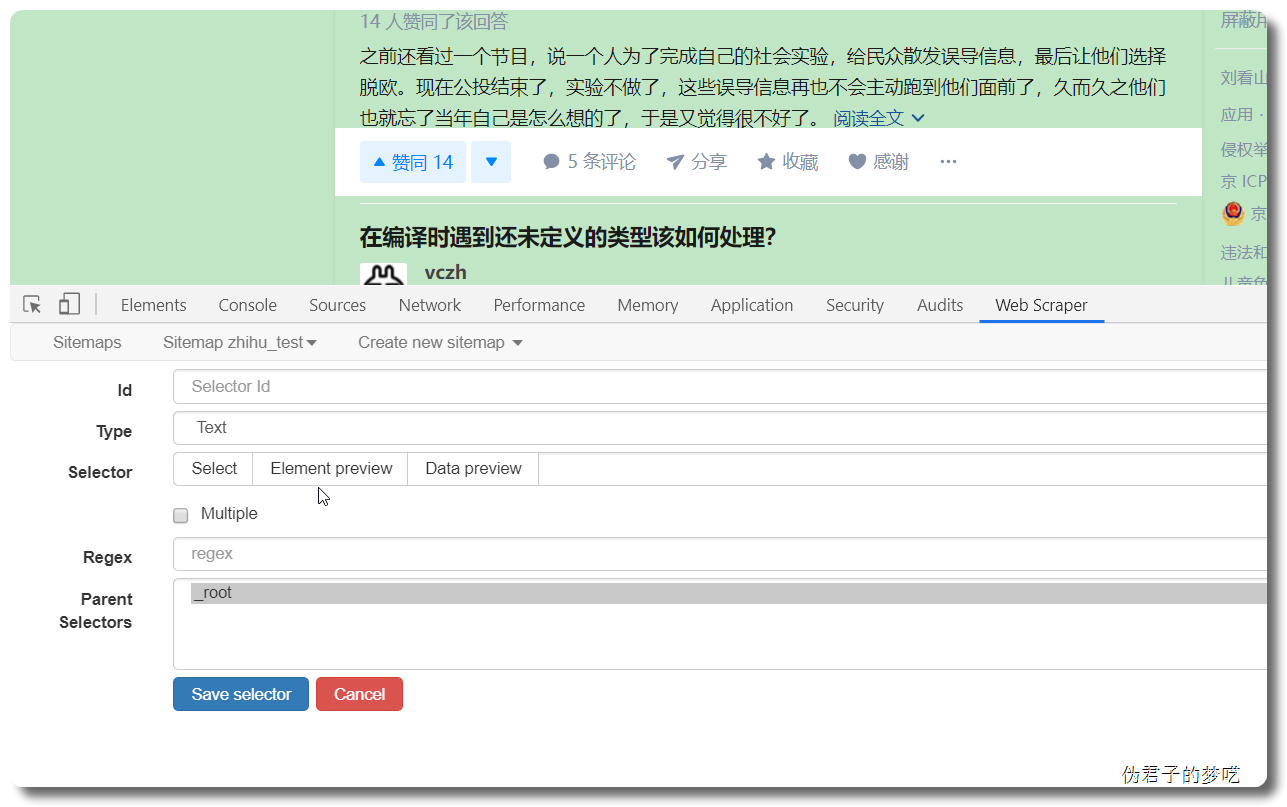
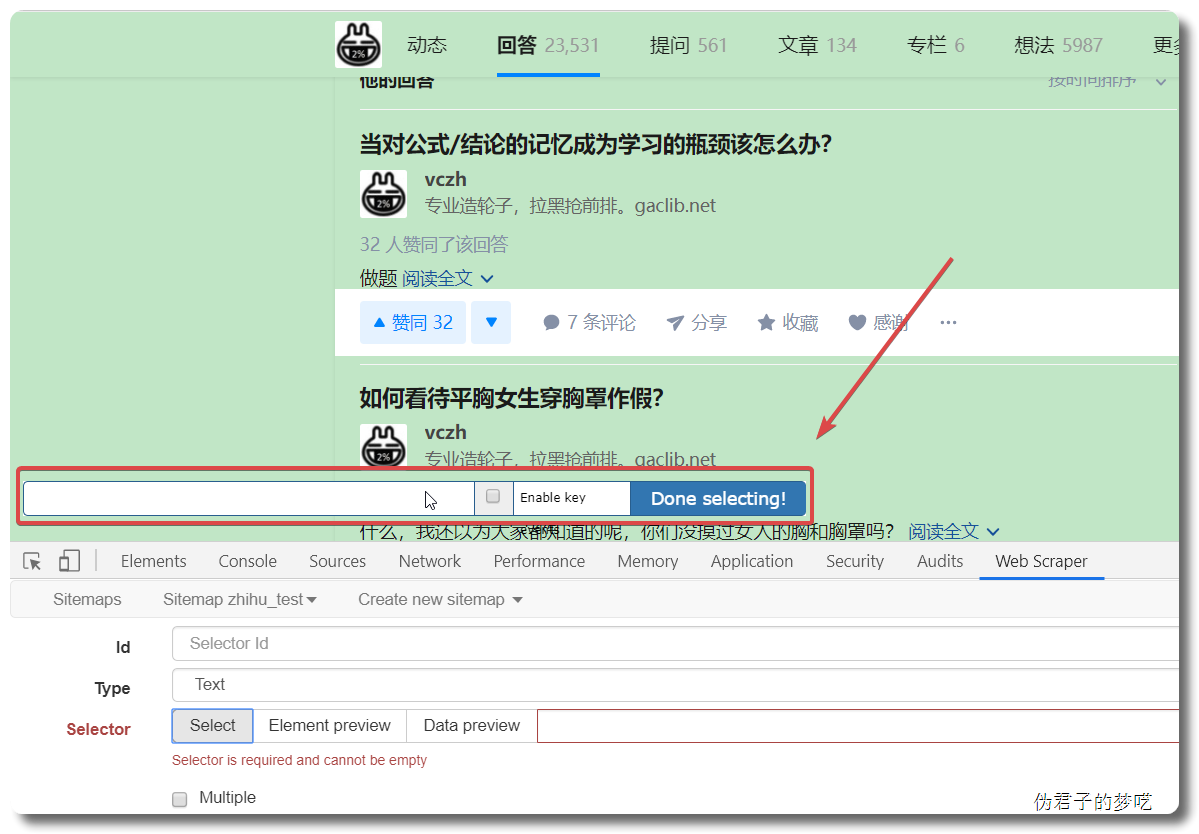
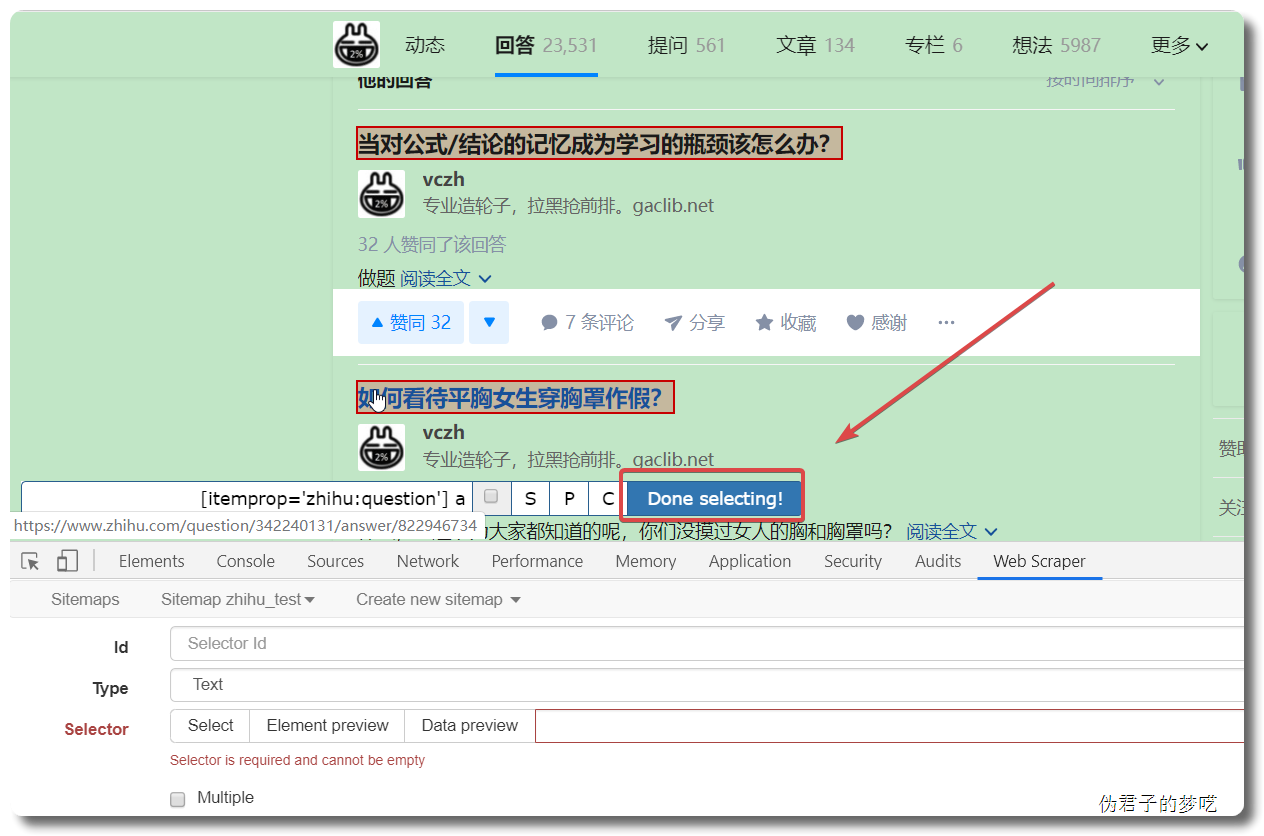
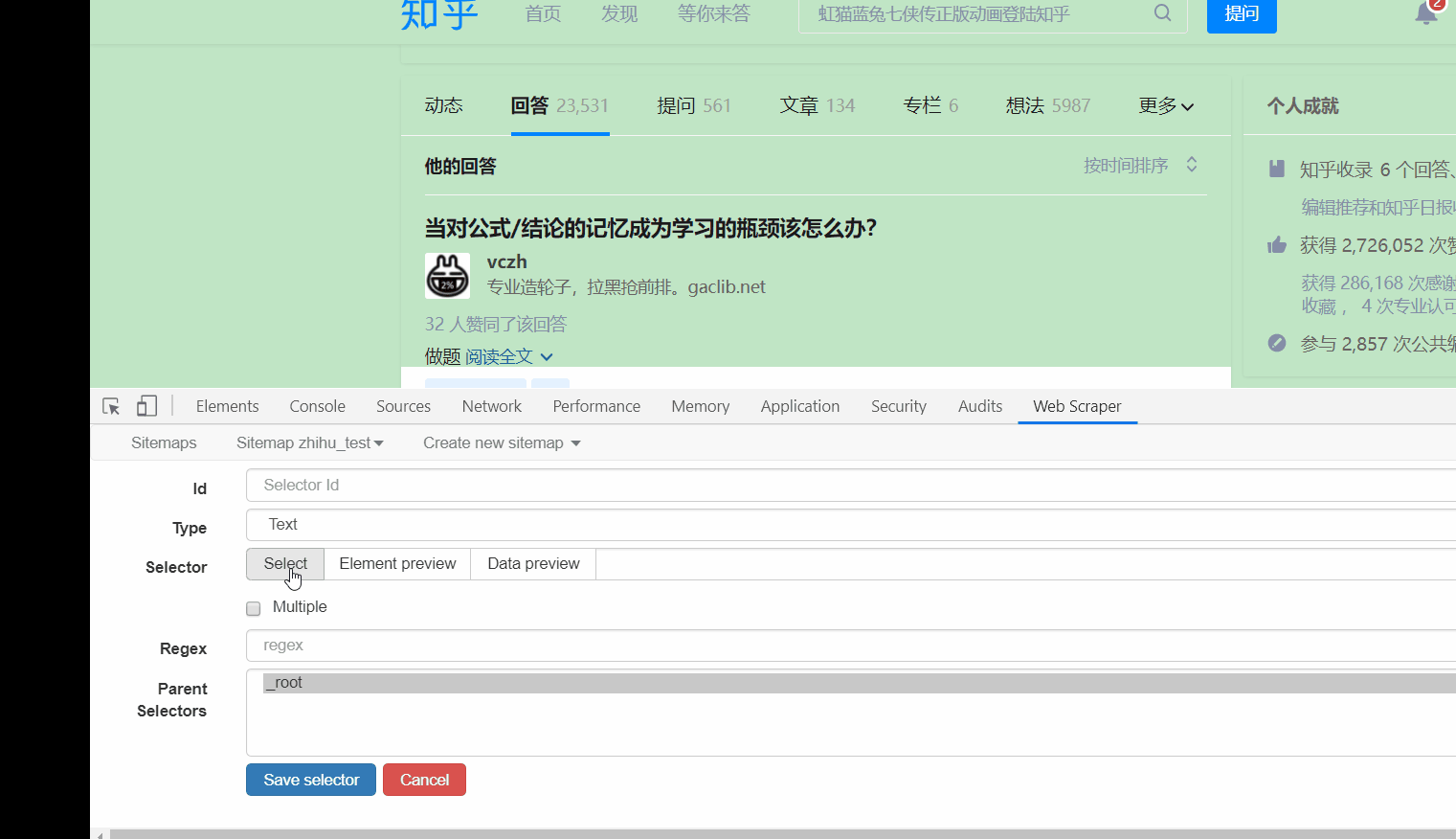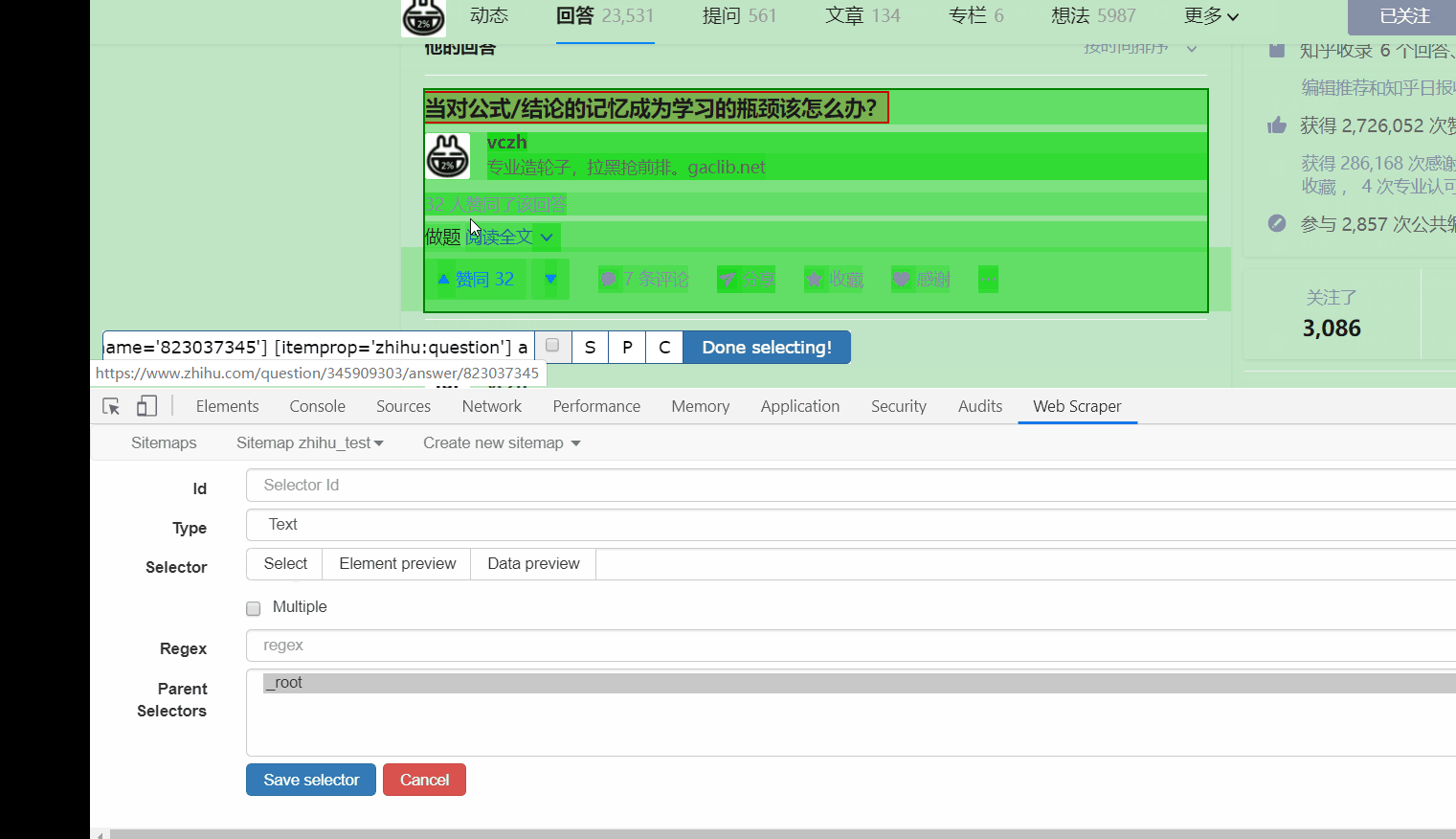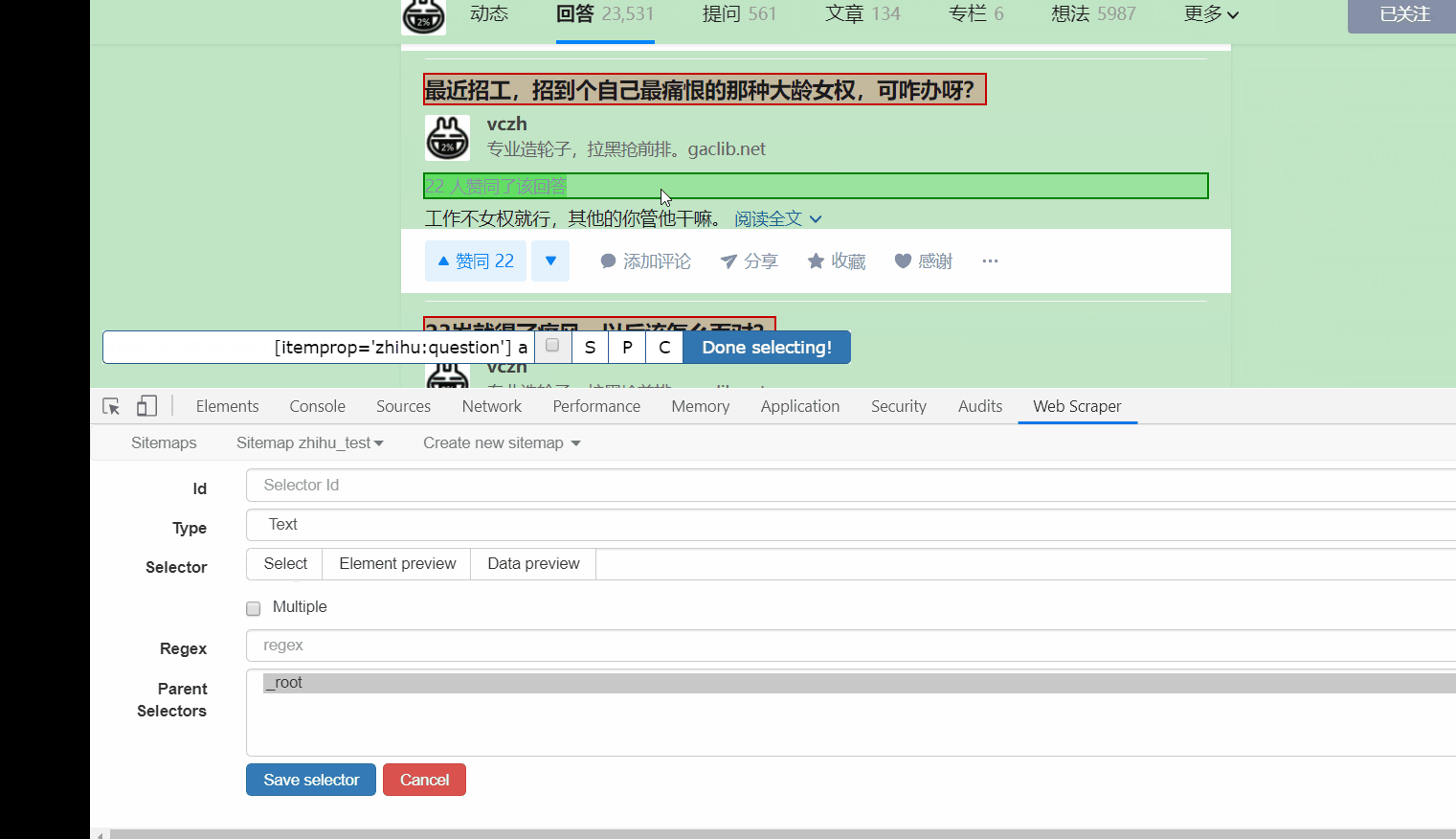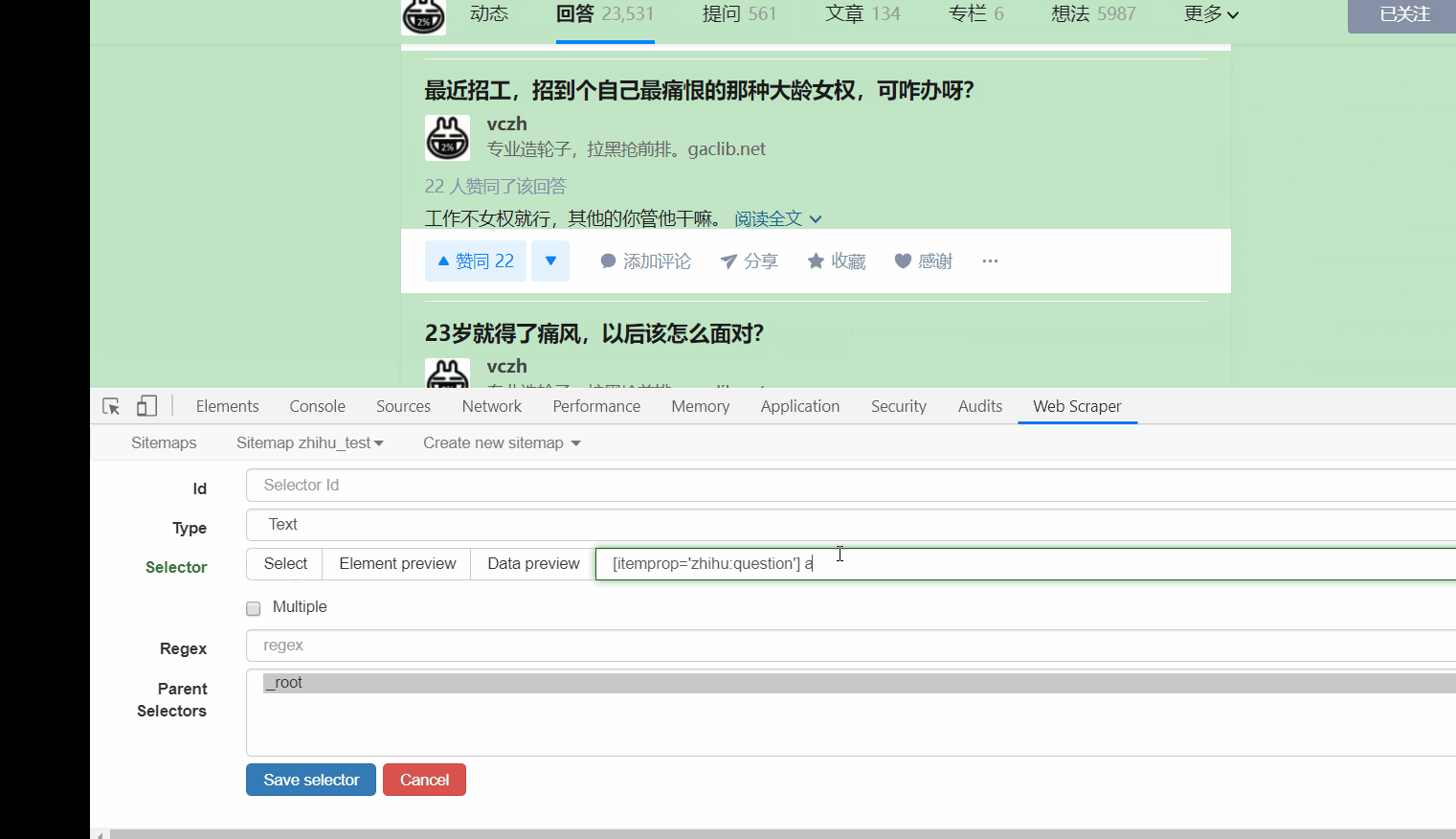
接下来的就是在 id 那填个名字,勾选一下 Multiple ,接着点击 Save selector。
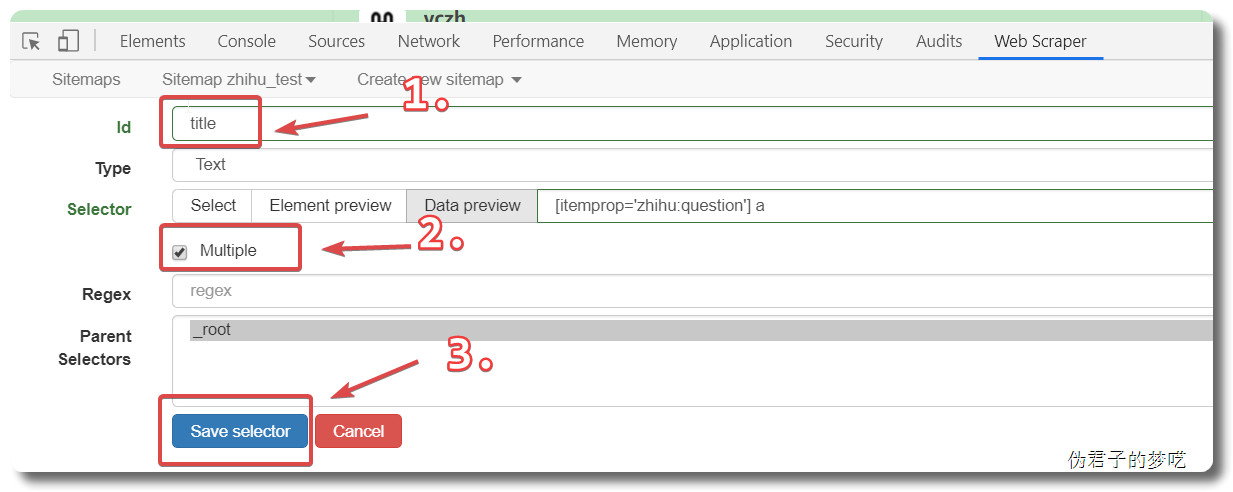
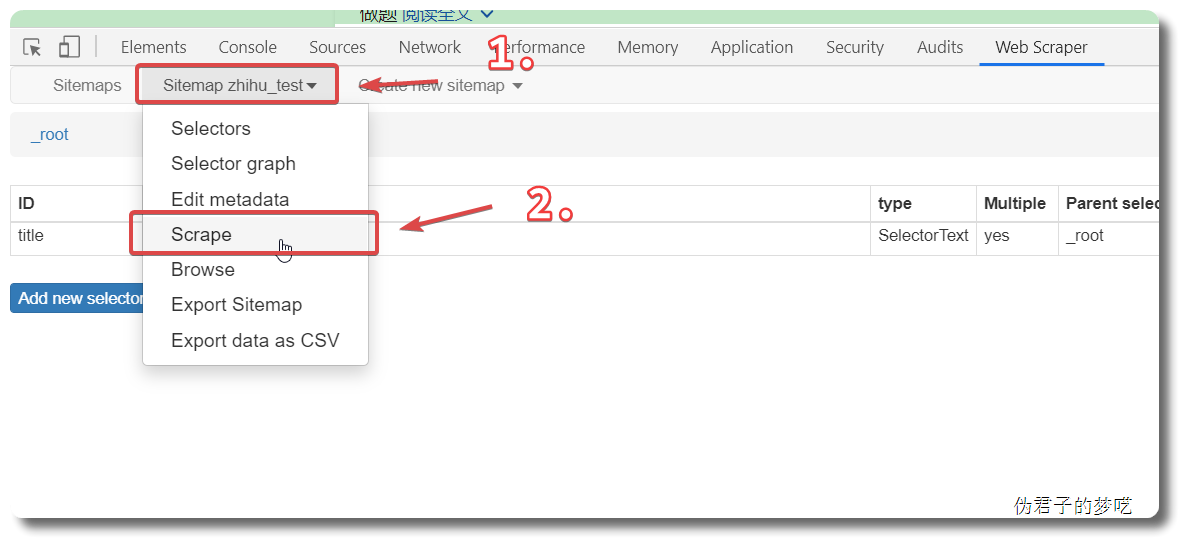

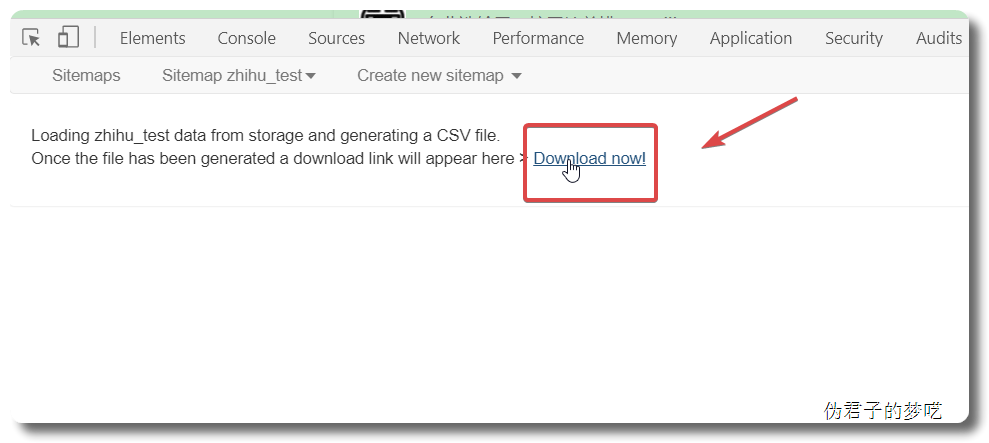
3 爬取更多页
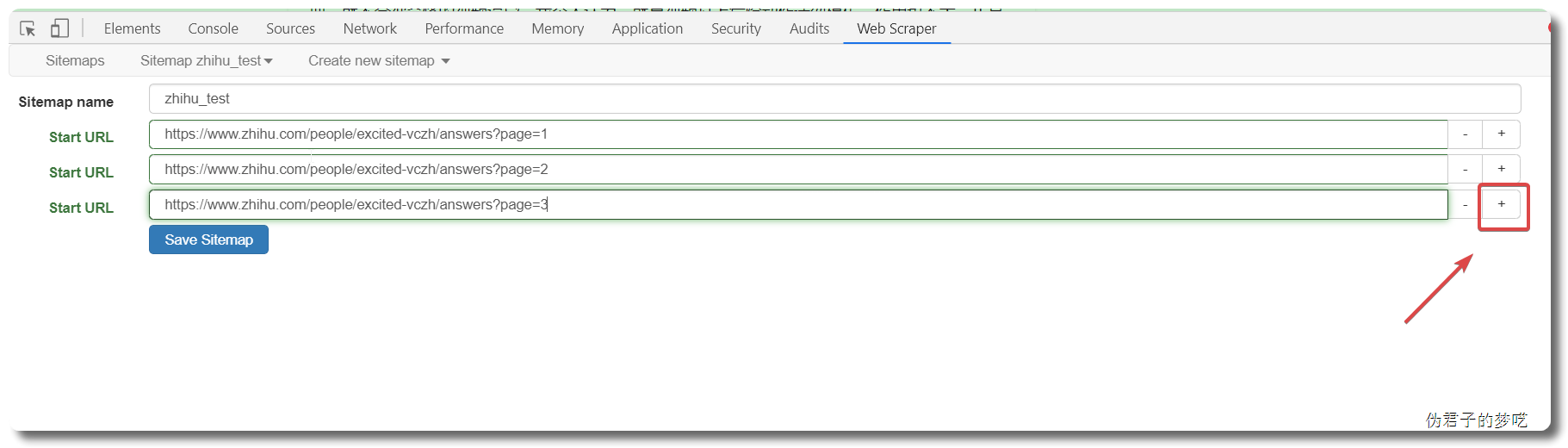
上面的只有一页,对不对,可以有更多页
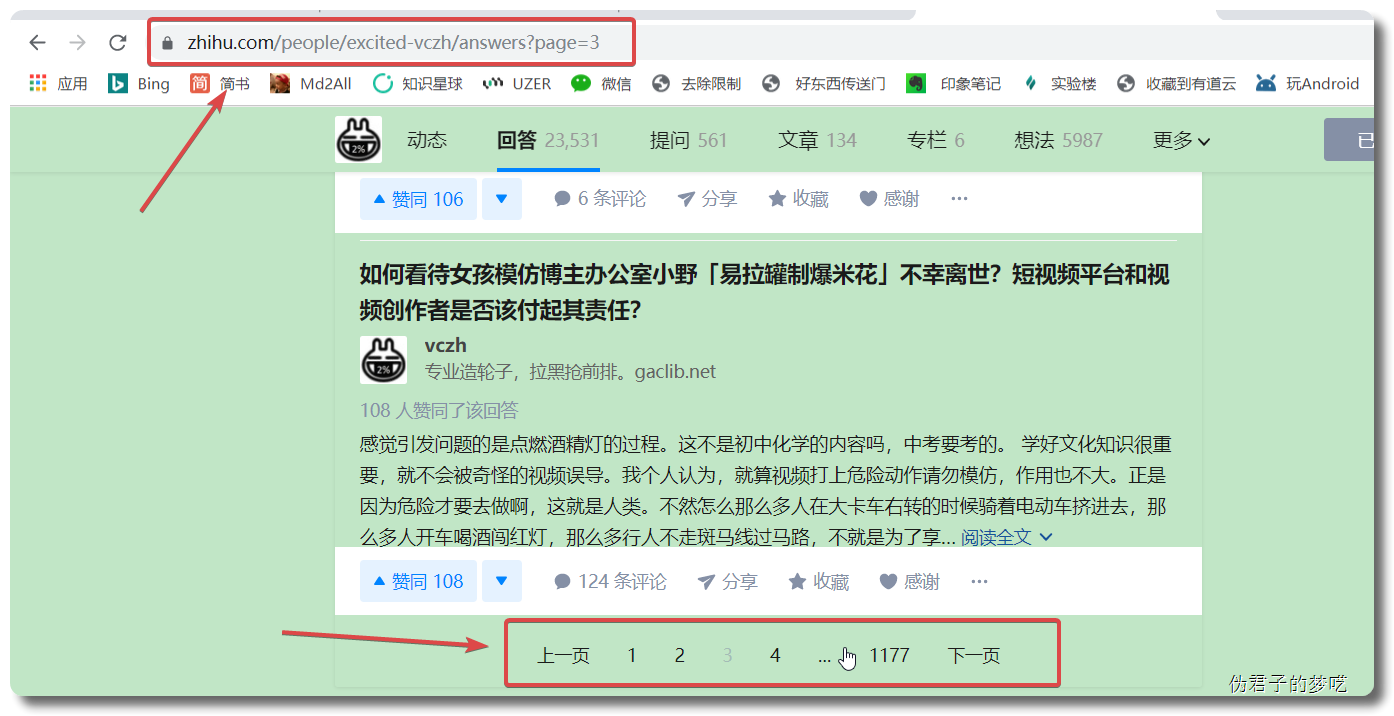
先来看一下页面链接的规则,
answers?page=1 answers?page=2 answers?page=3 answers?page=4
这个是有顺序的
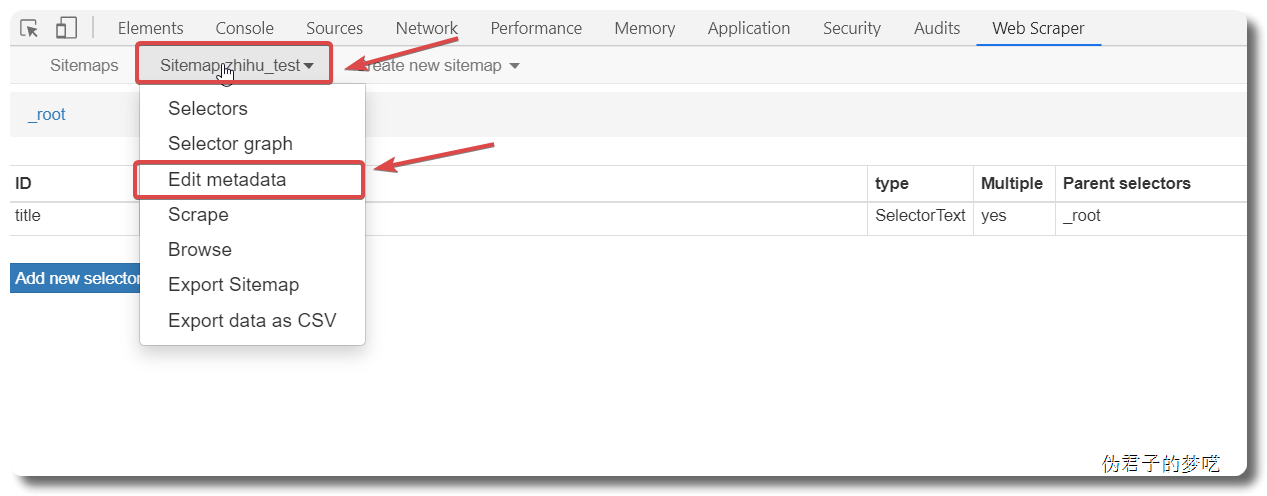
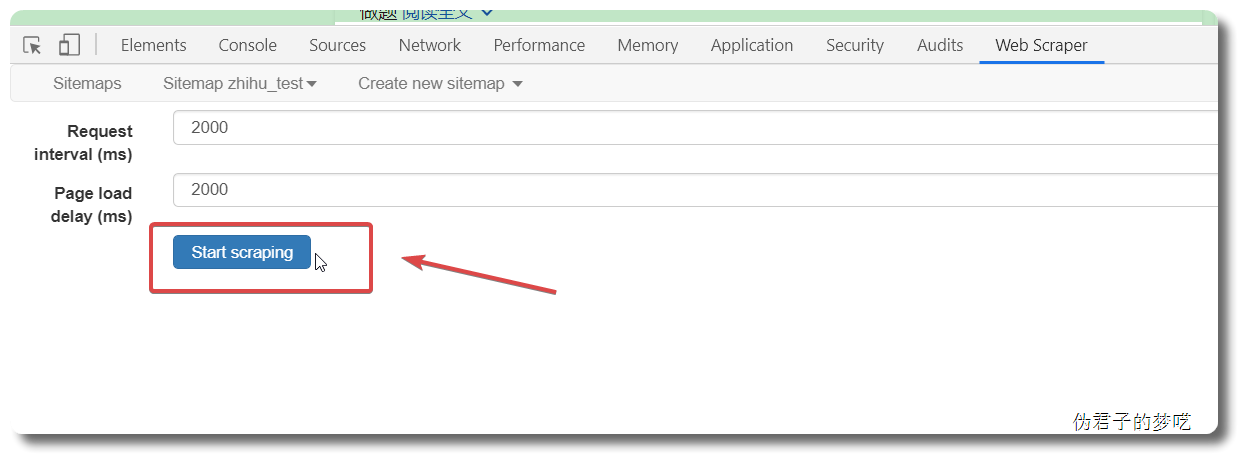
Save sitemap ,然后去 Scrape
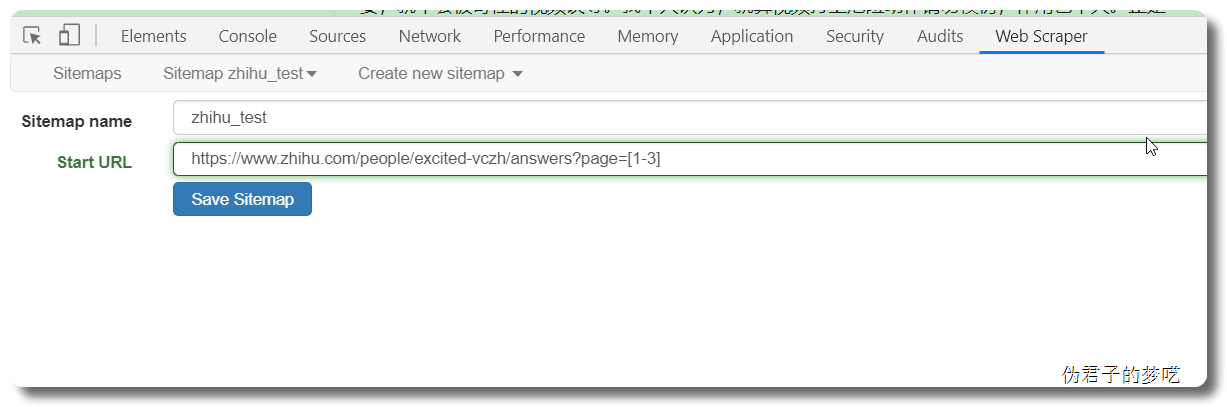
Edit metadata,进入去修改一下,把链接改成 https://www.zhihu.com/people/excited-vczh/answers?page=[1-3]
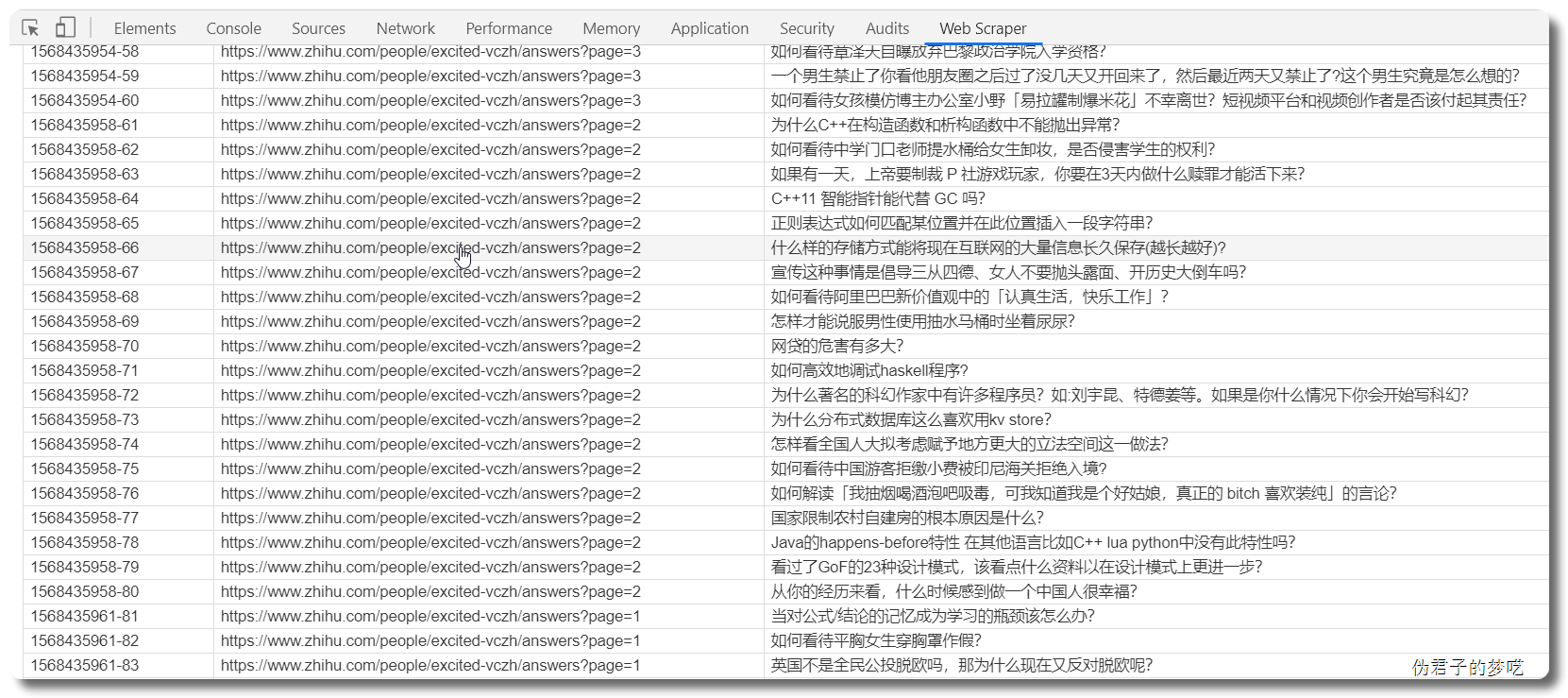
然后保存,运行一下看看。
4 爬取更多的数据
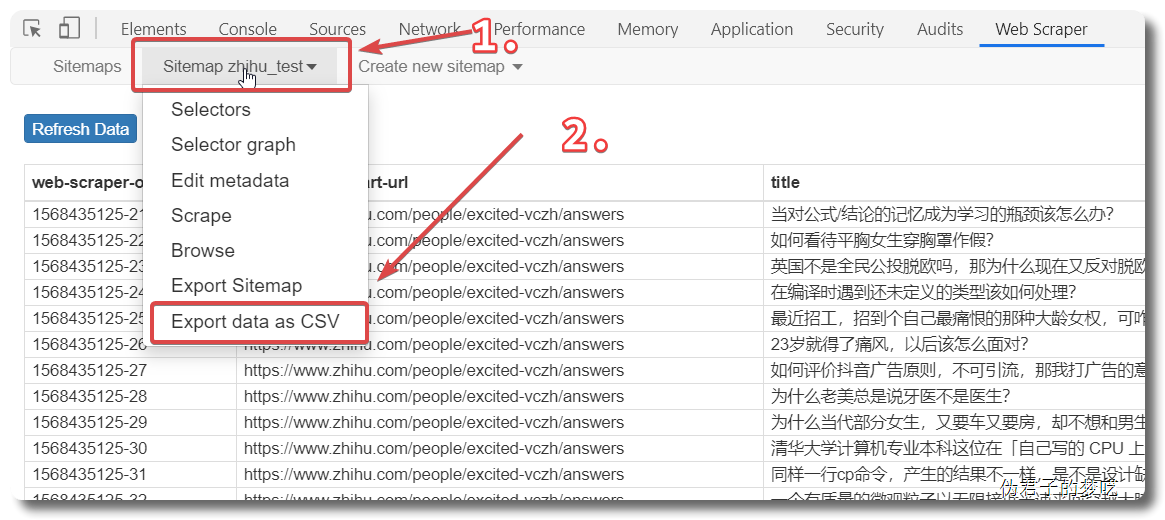
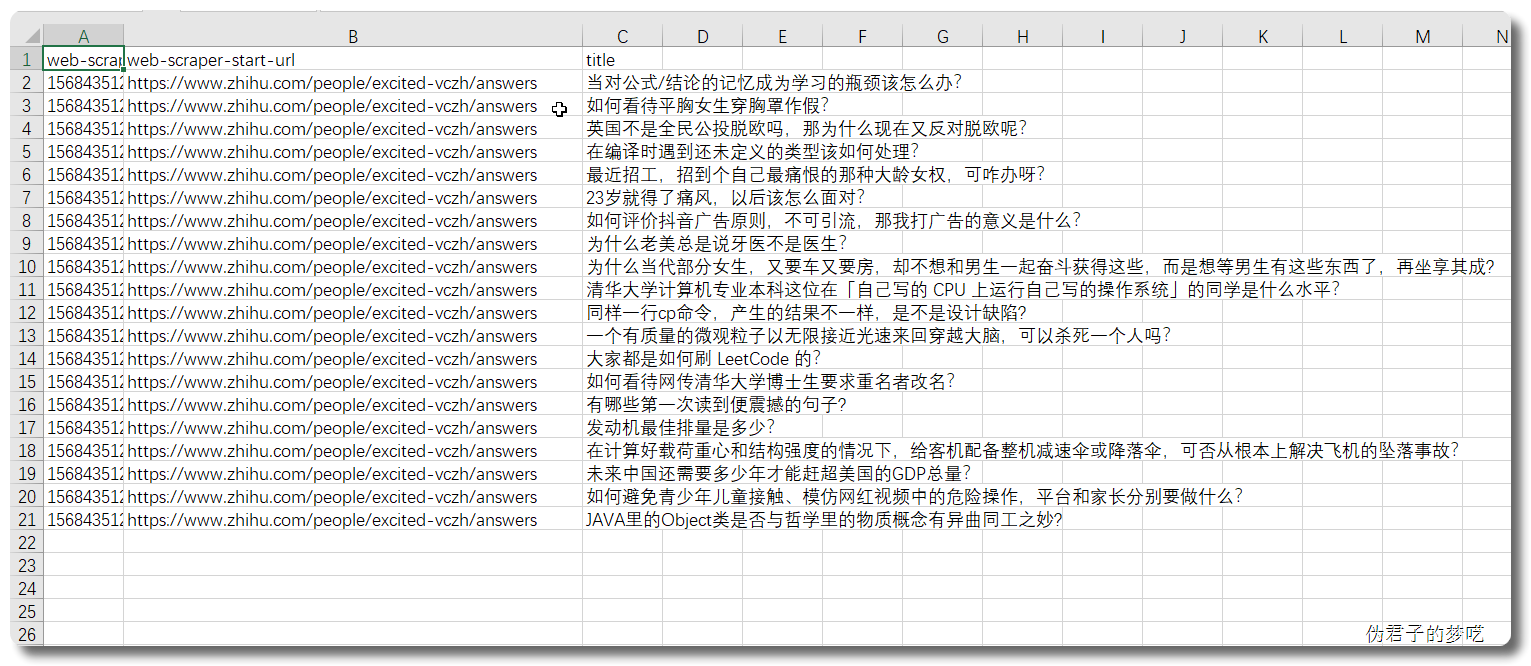
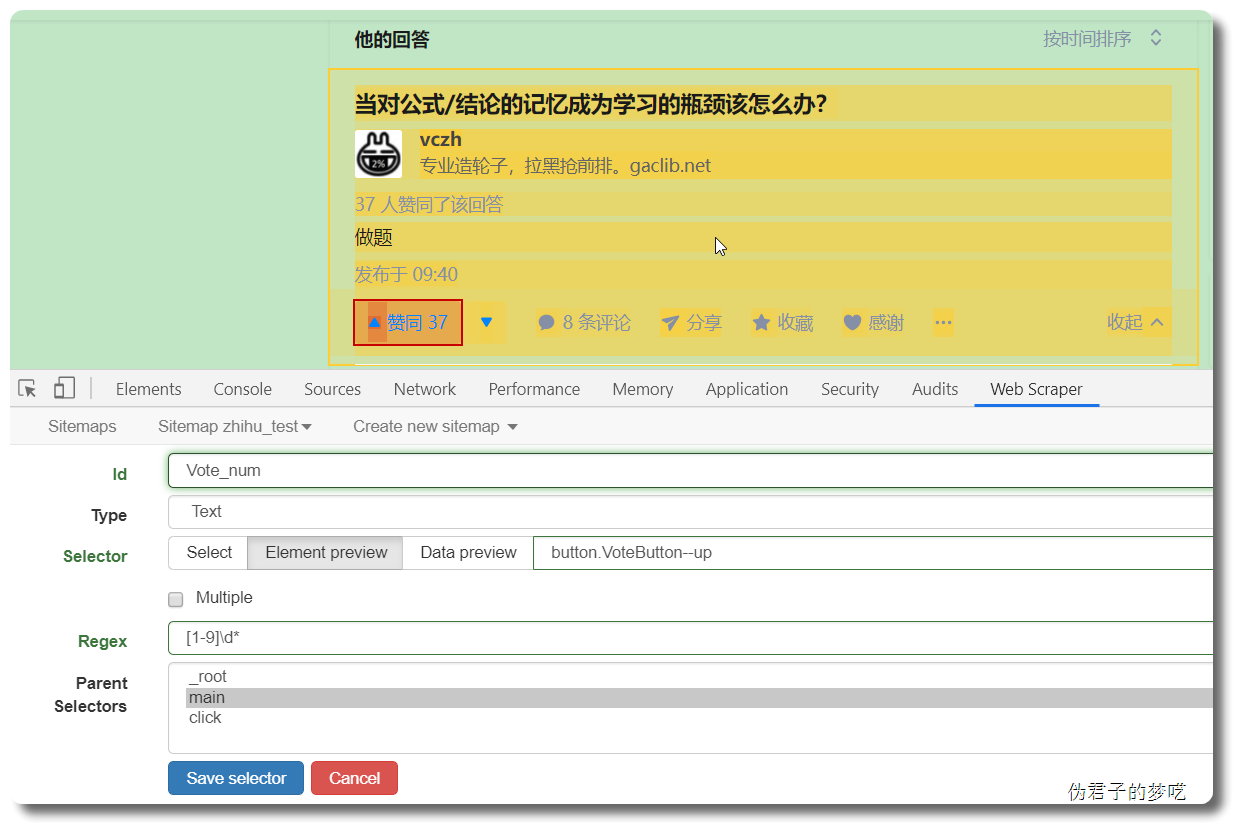
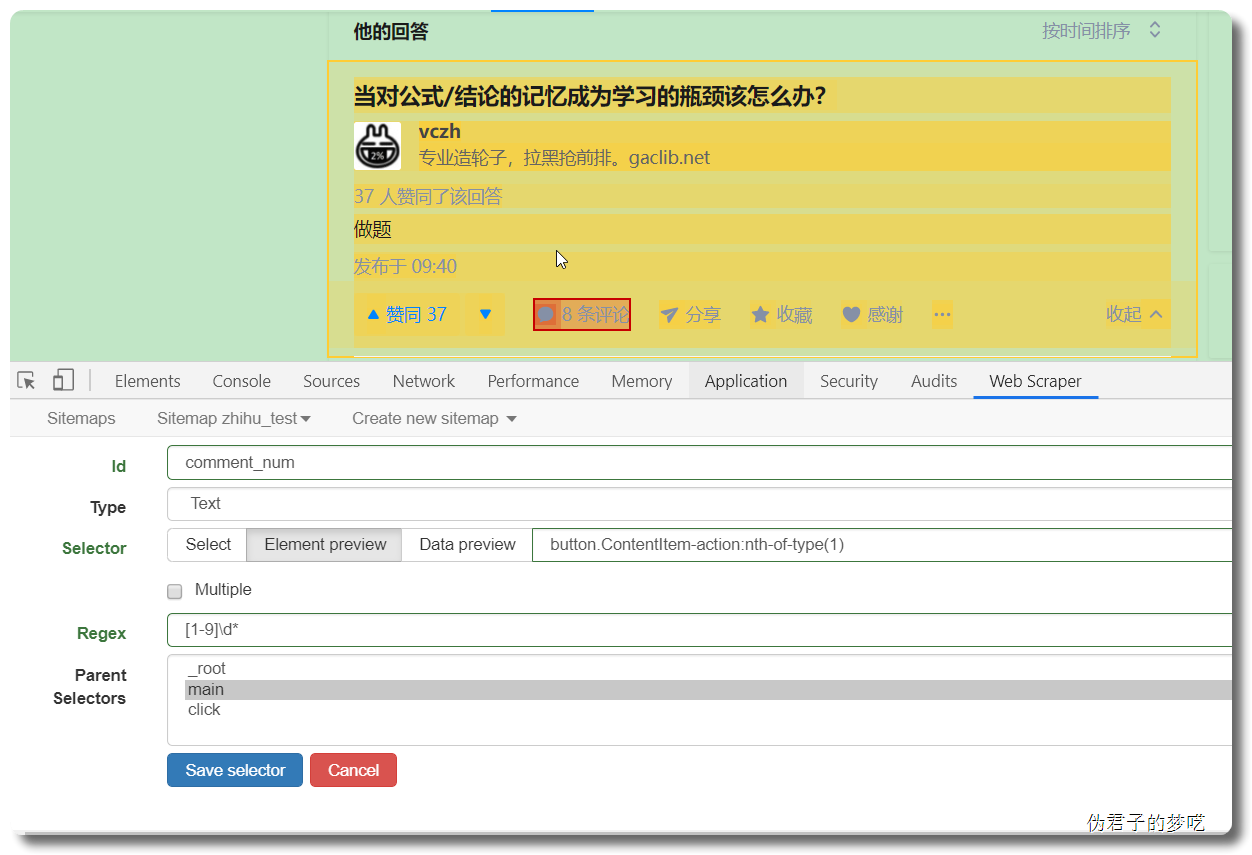
显然,上面的数据只有一个 title,没有回答的内容,也没有点赞/评论数
所以得加上,再创建一个 sitemap,或者直接把刚刚的 title 删掉,回到最初的起点,Add new selector
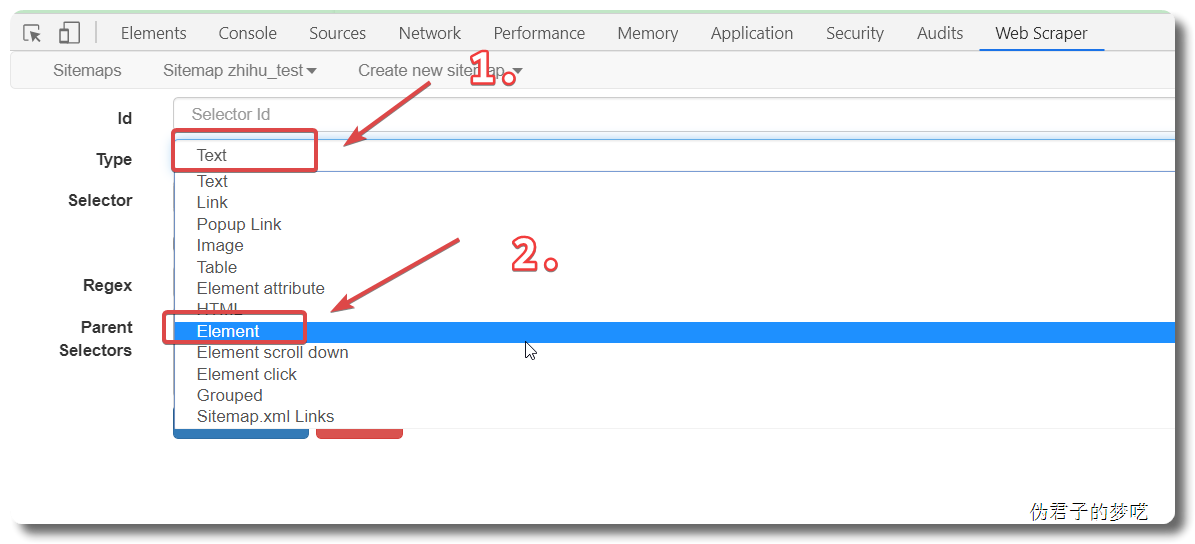
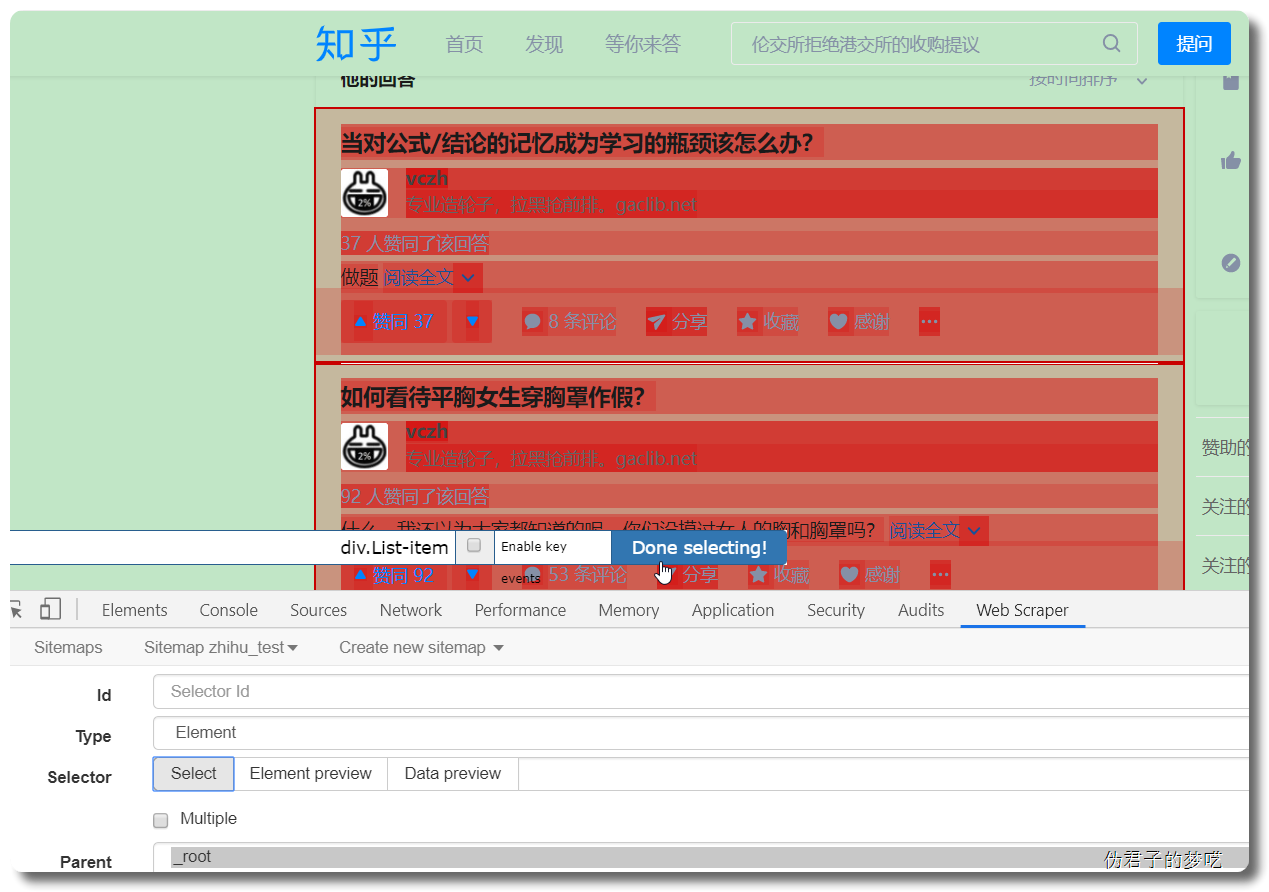
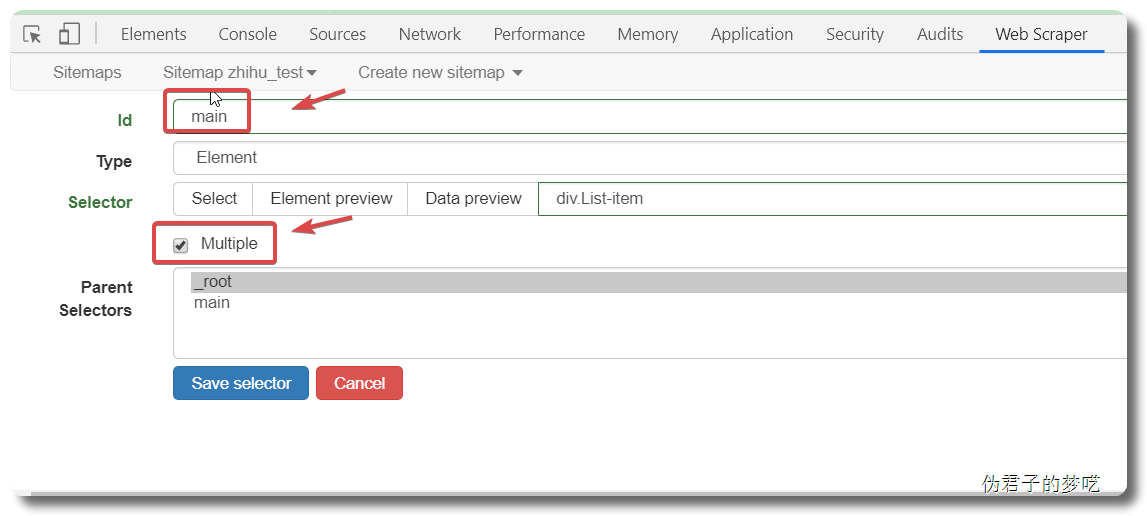
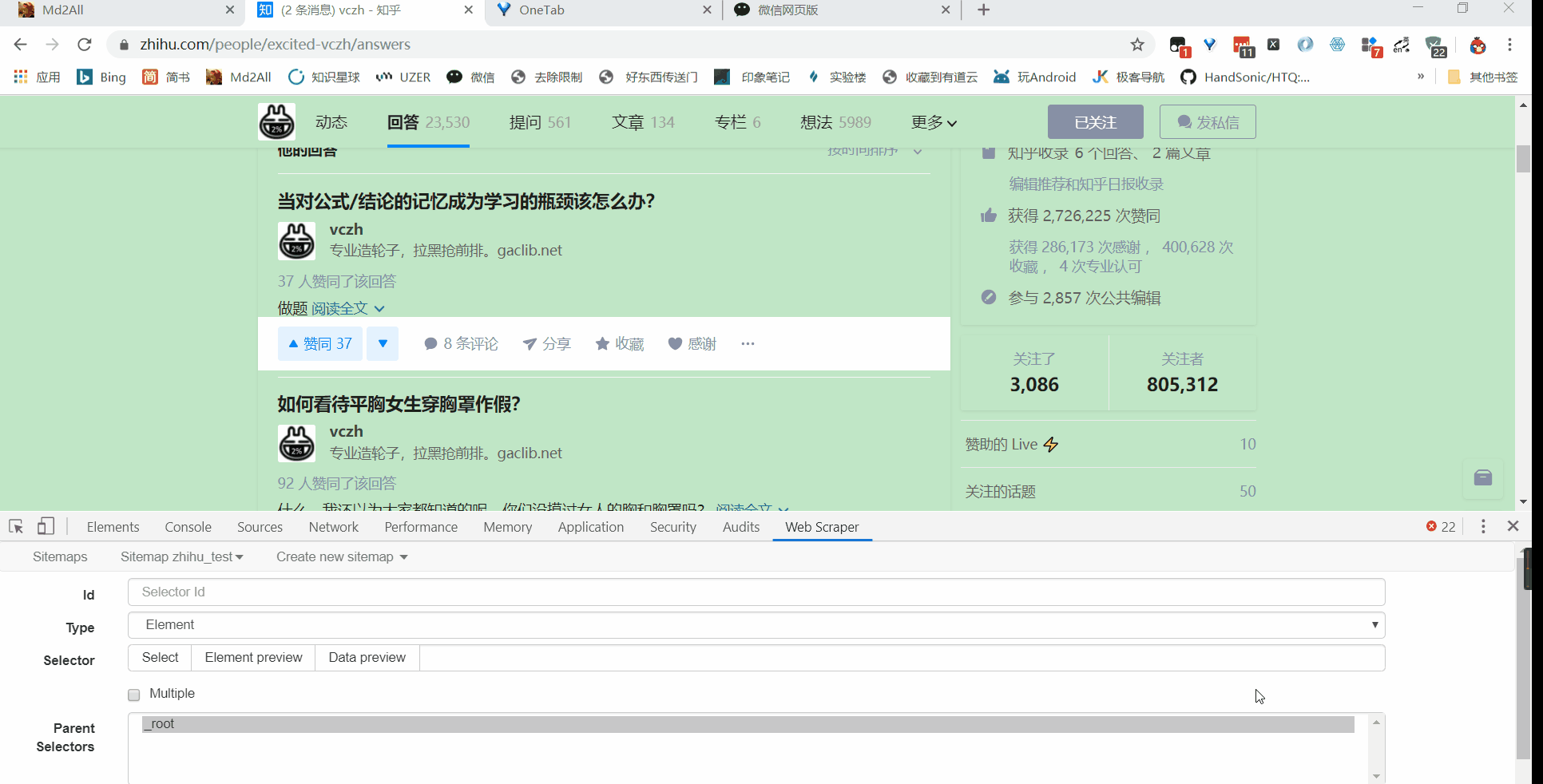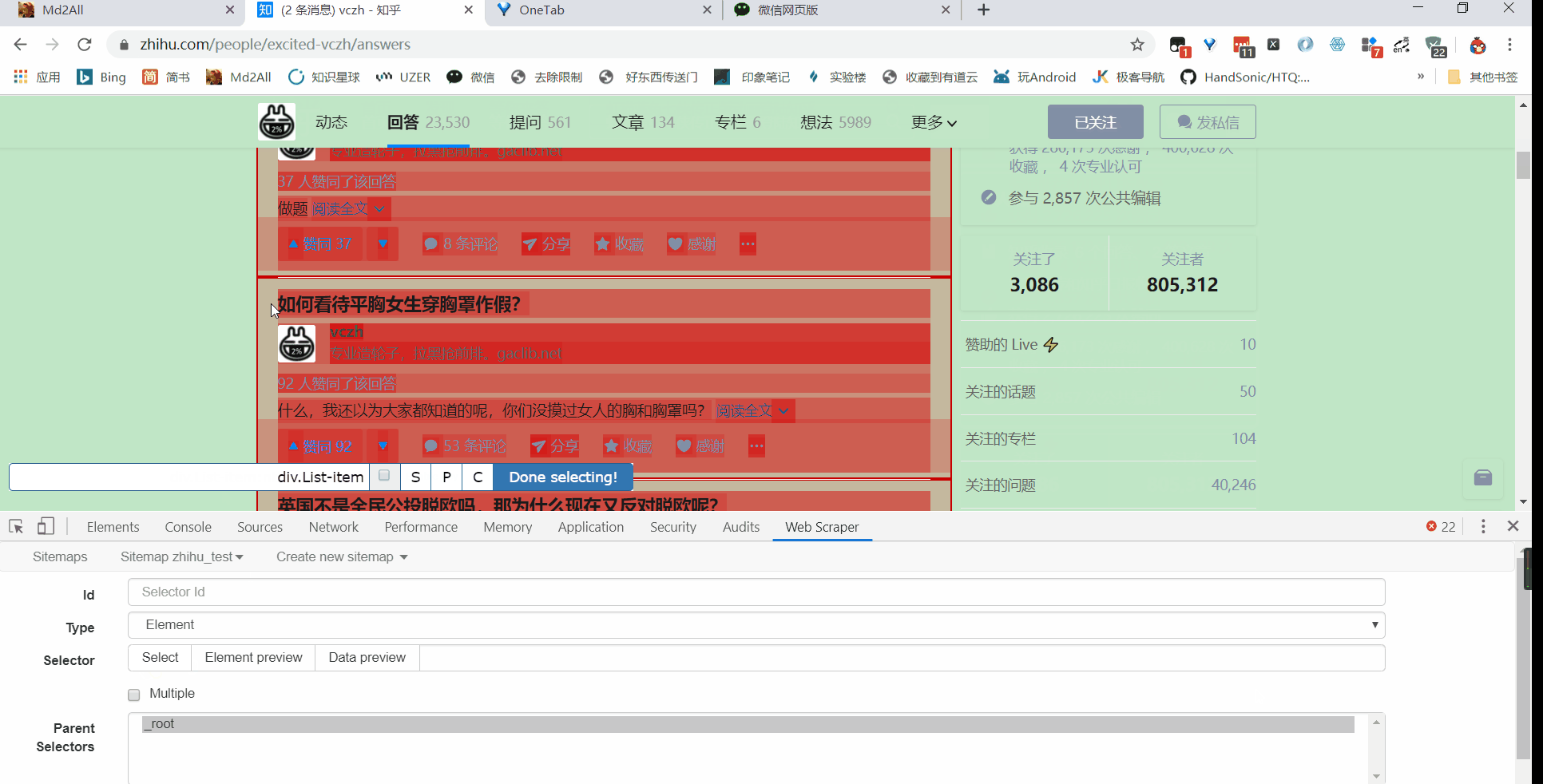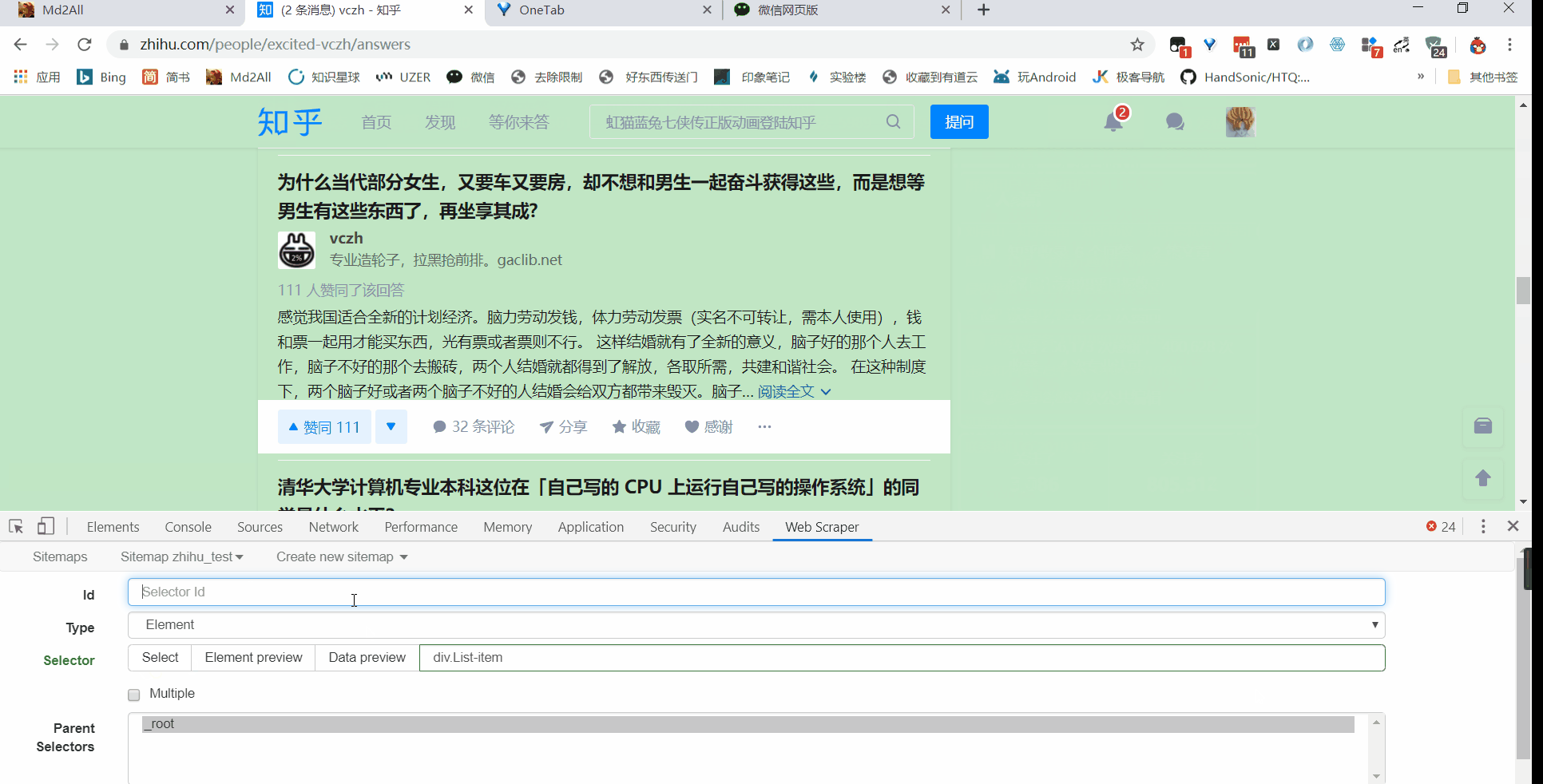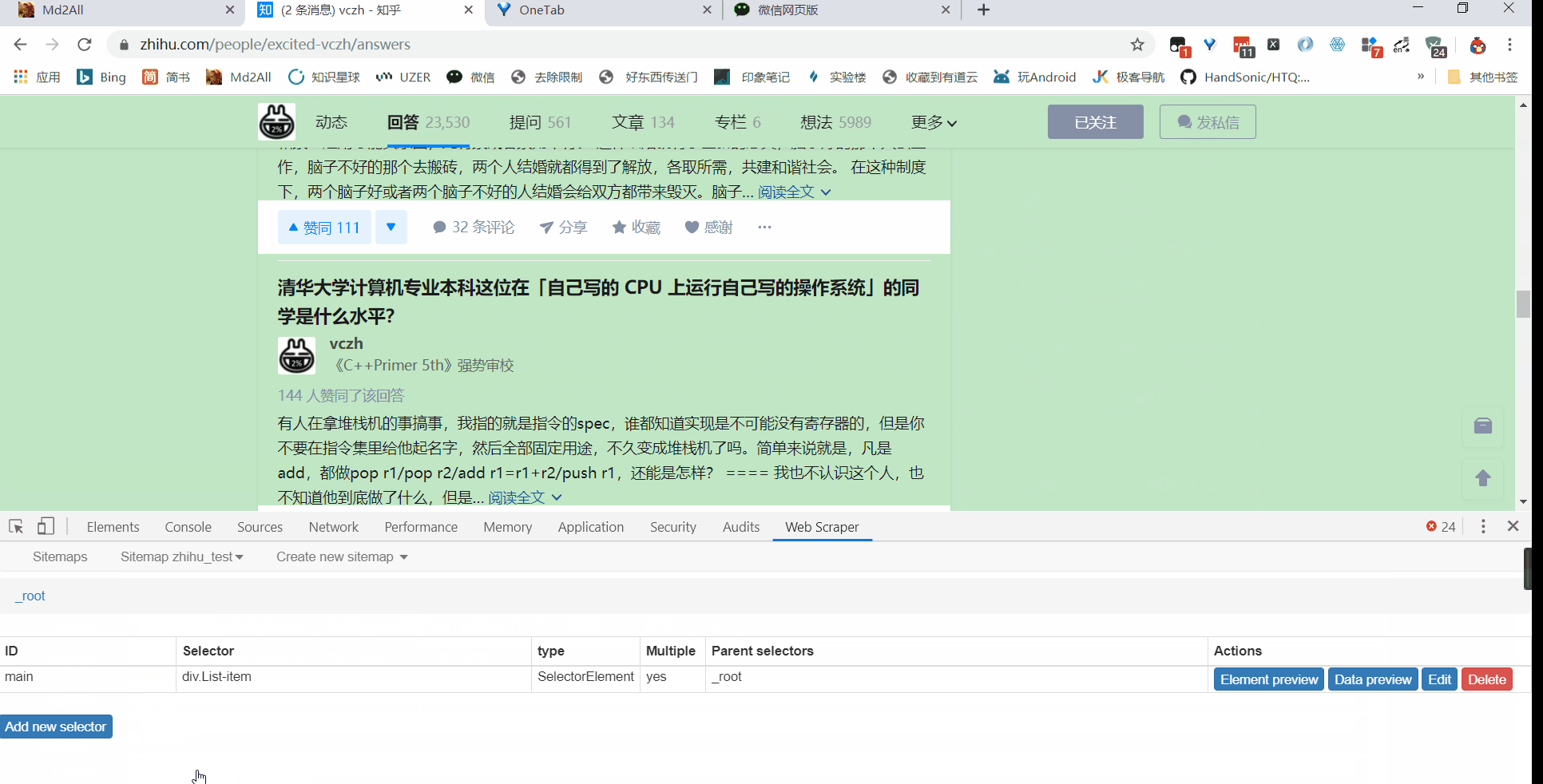
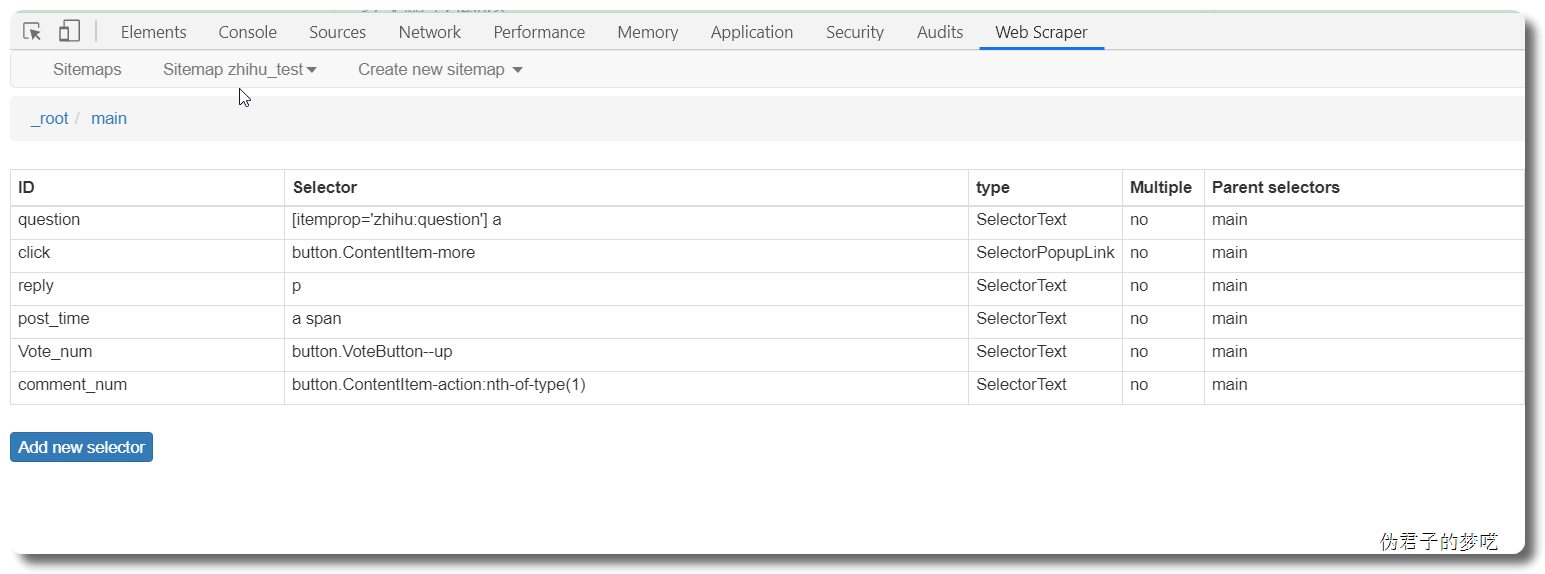
接着就是点击刚刚创建的 selector,进入里面
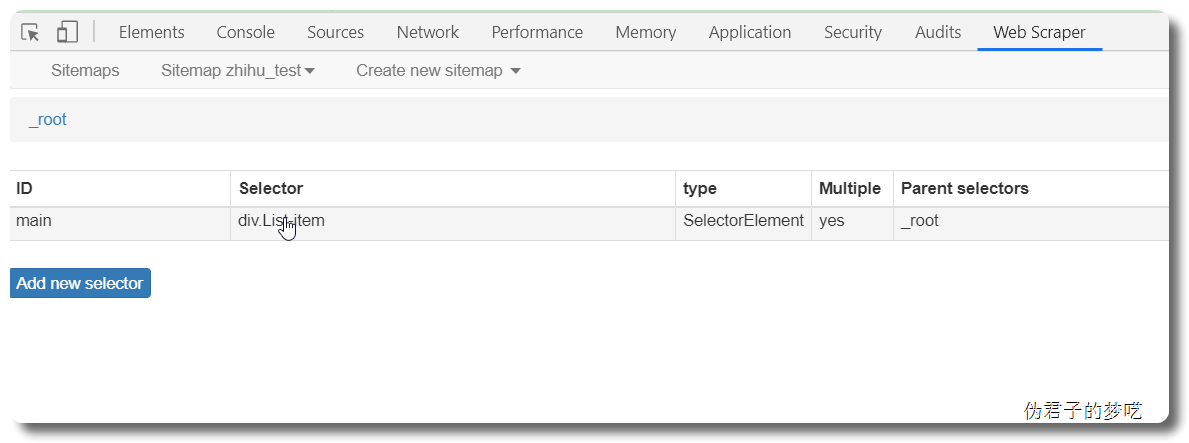
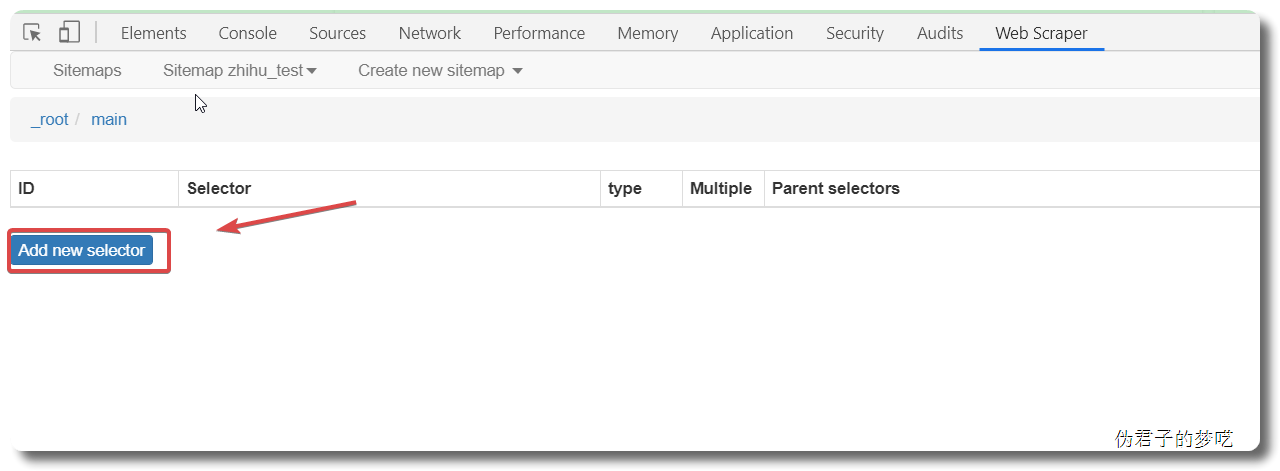
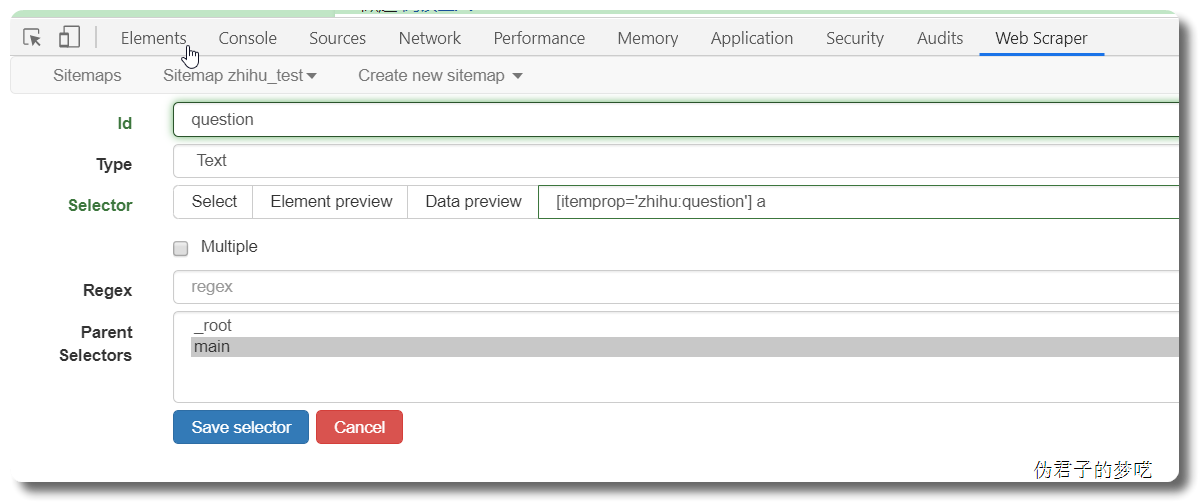
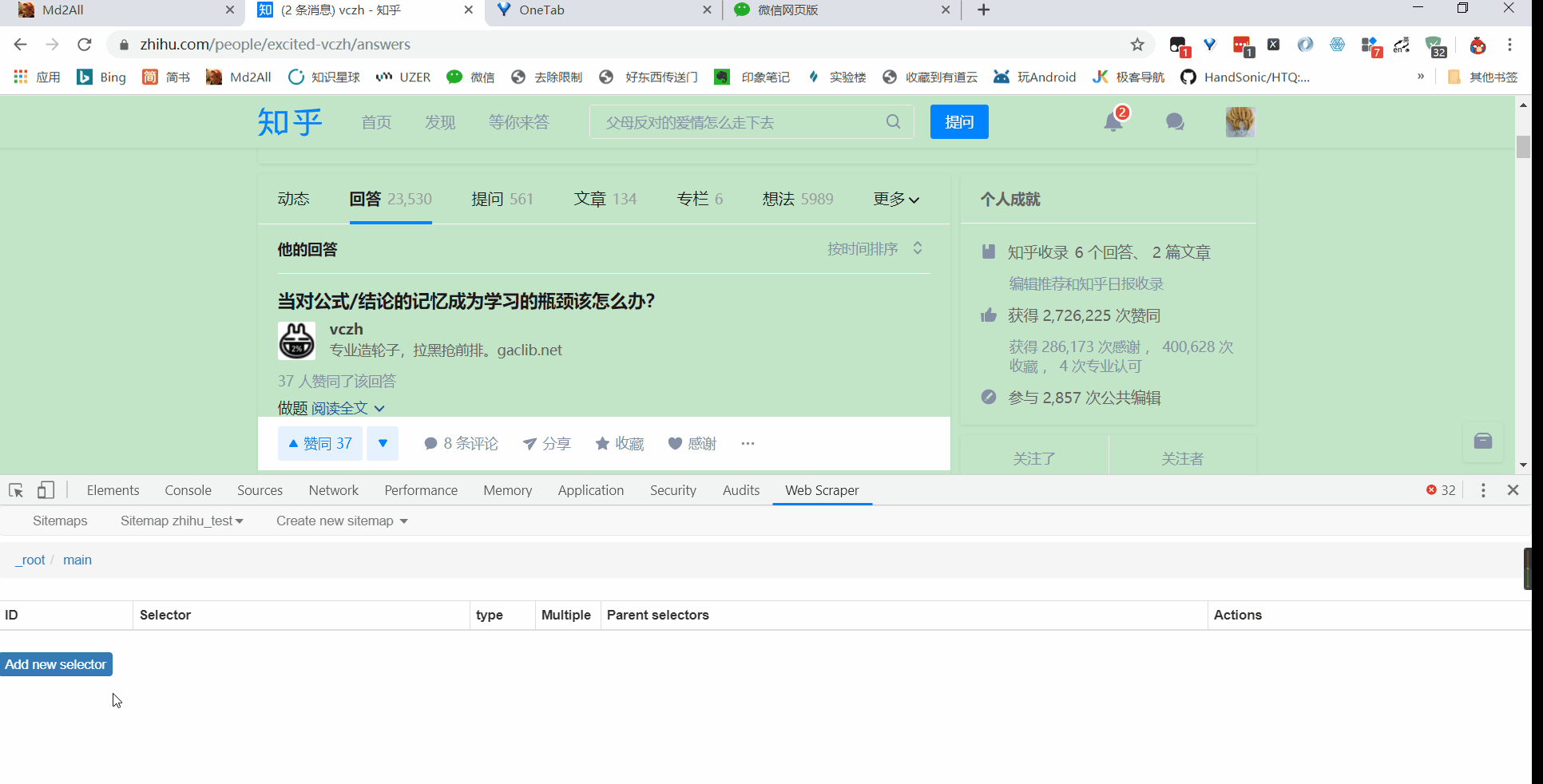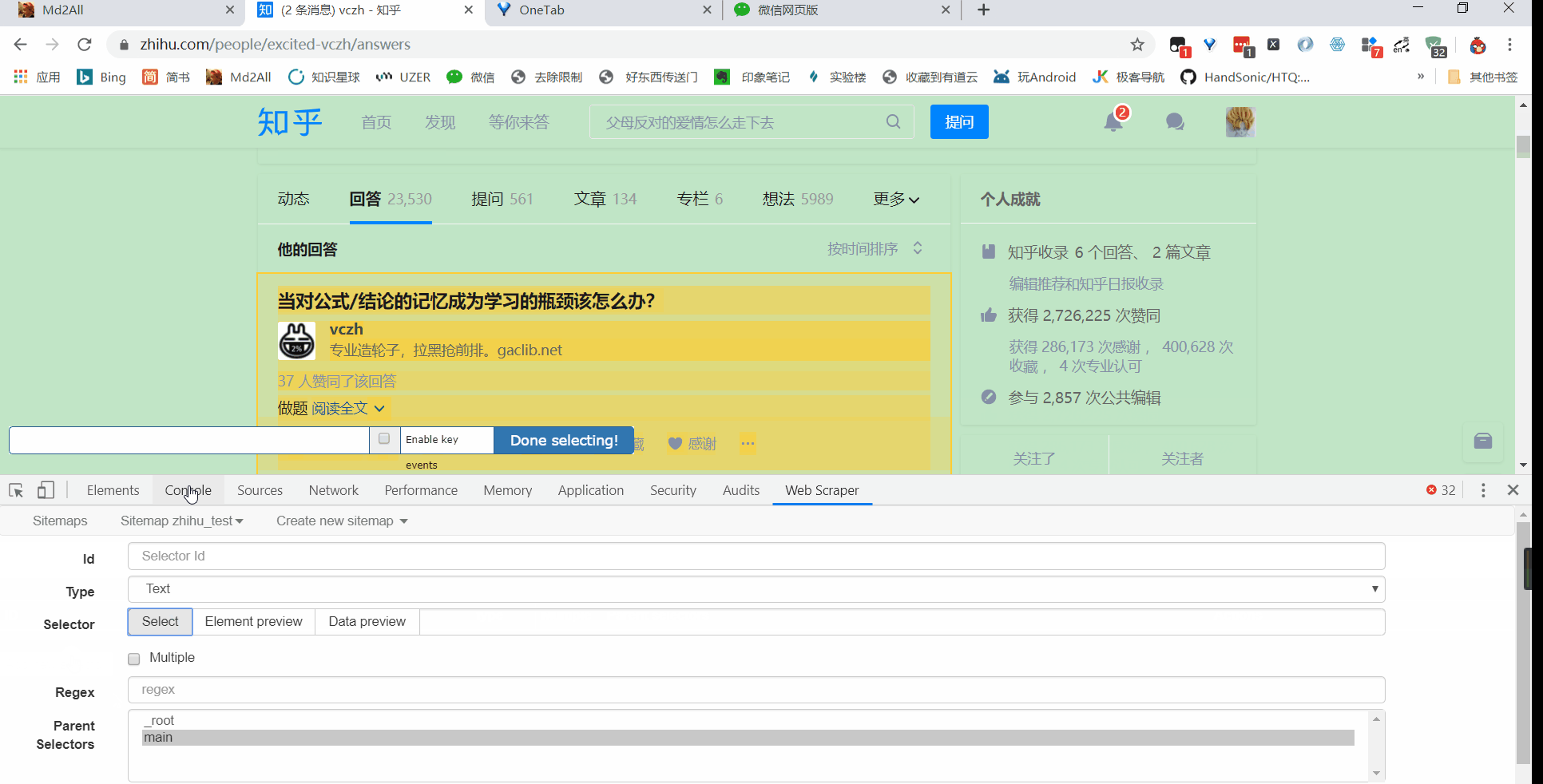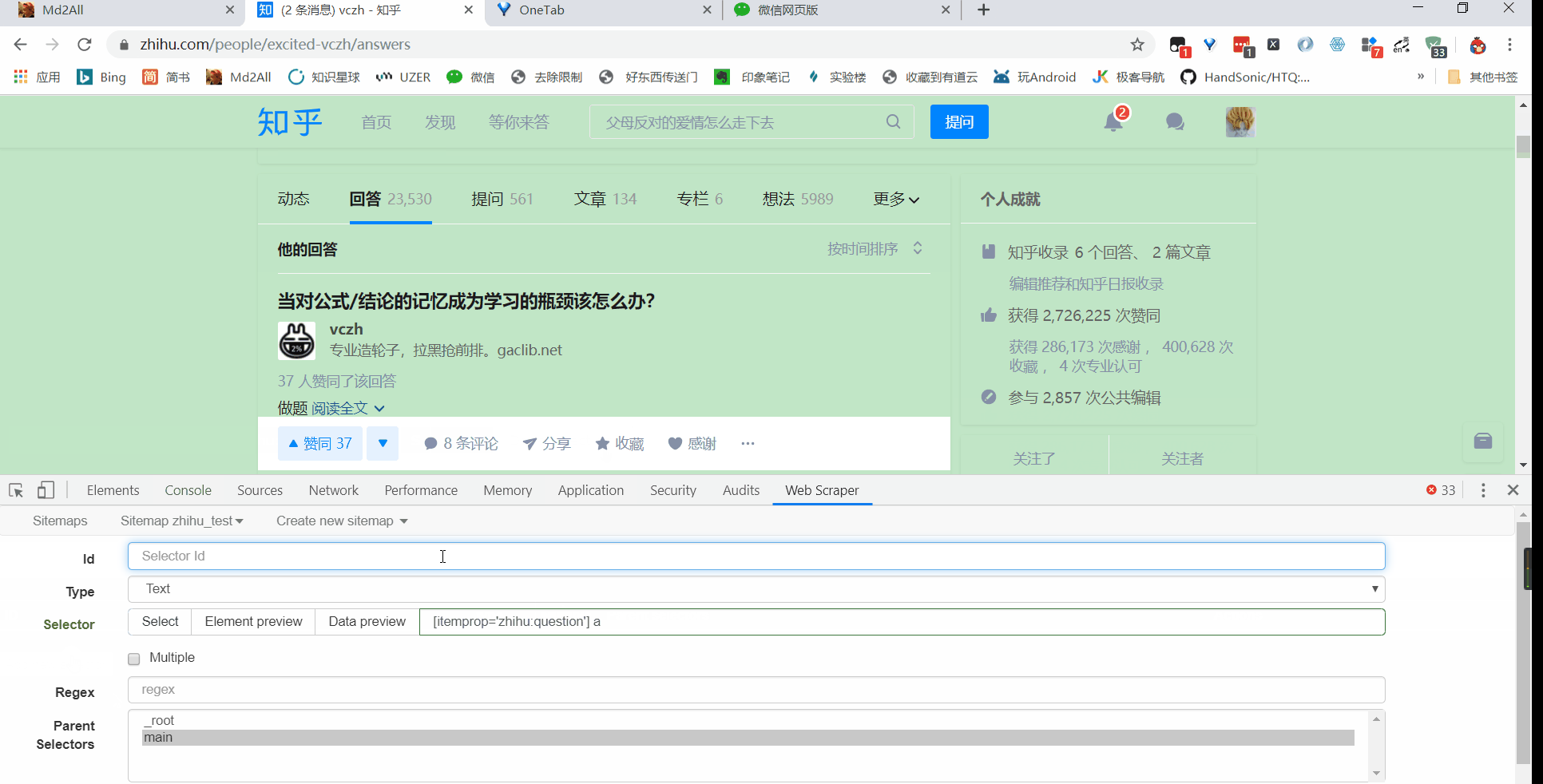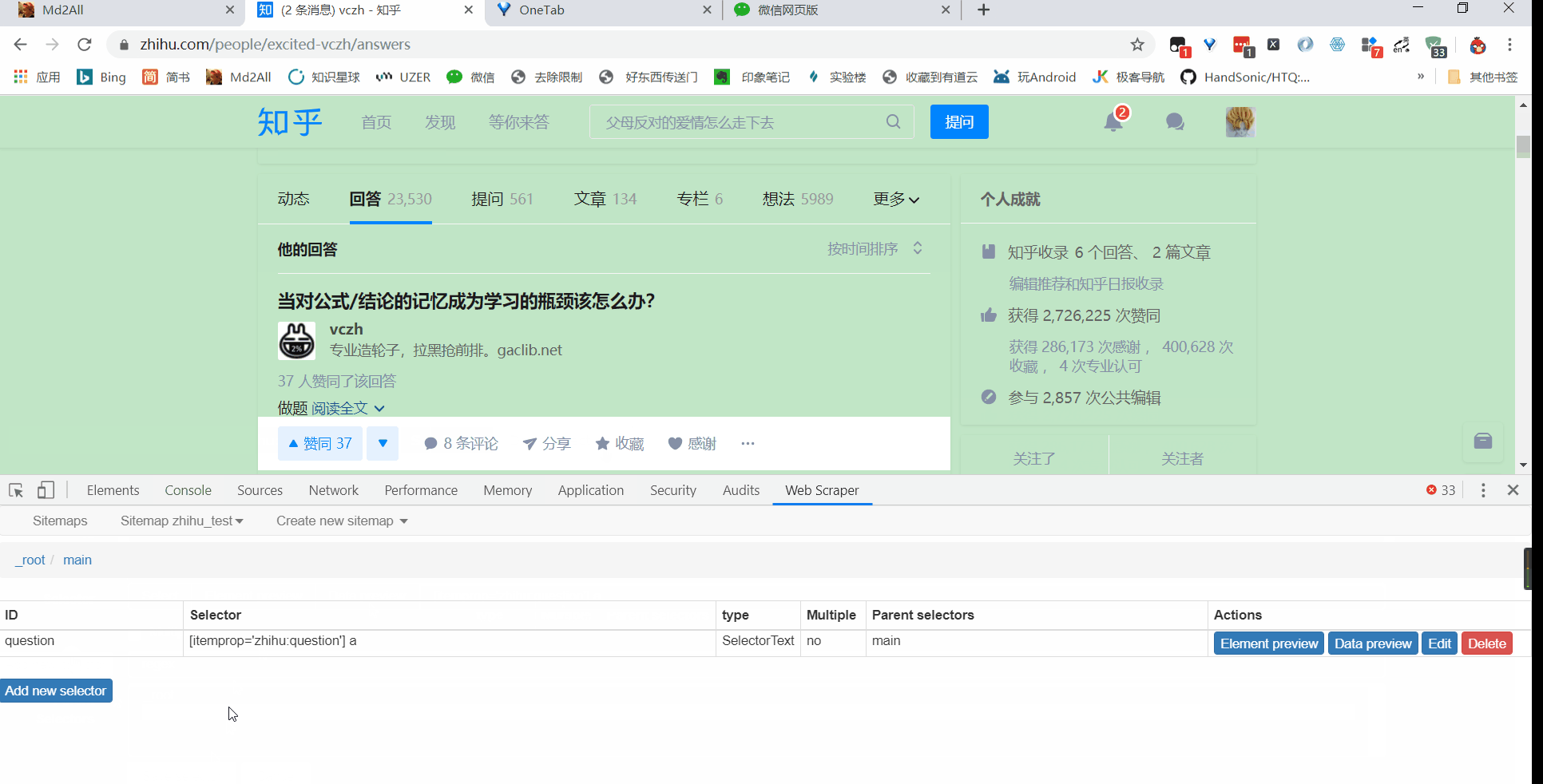
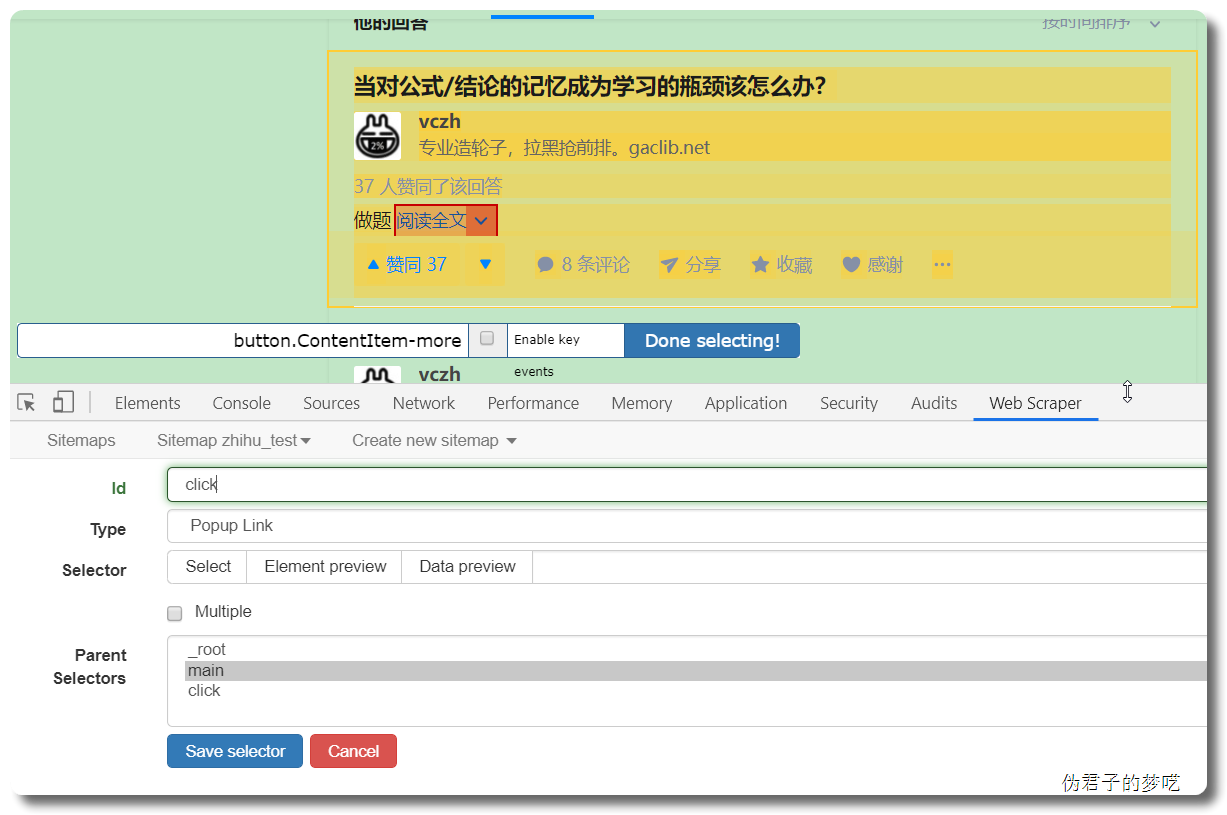
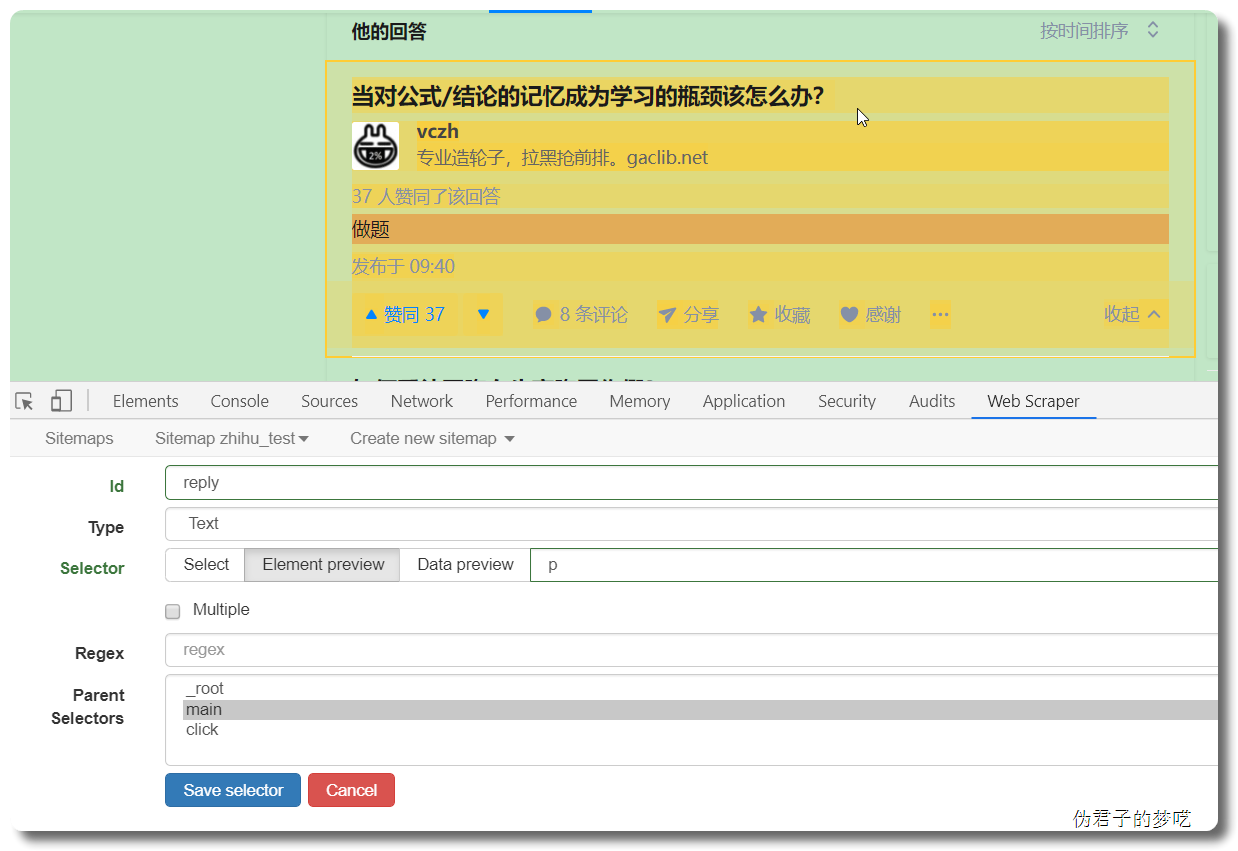
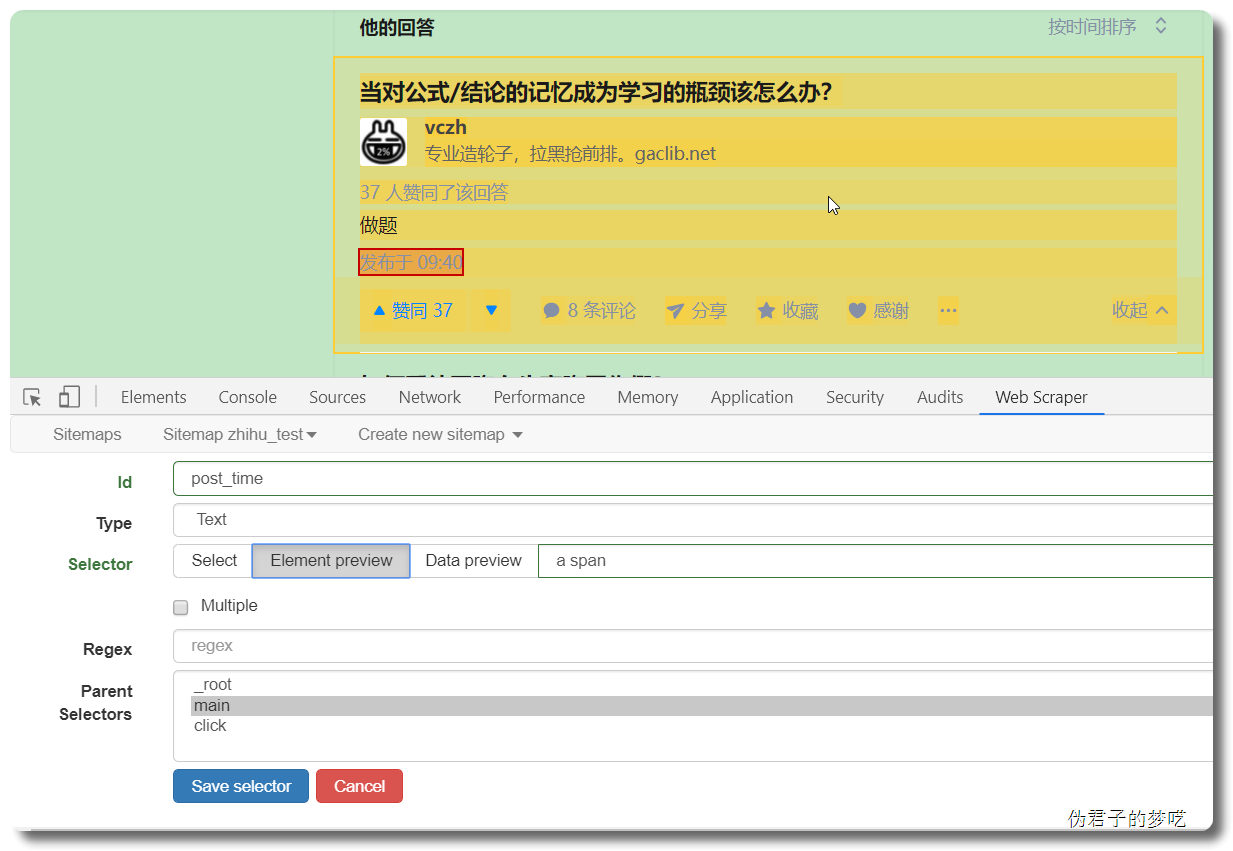

5 相关说明
显然,你们爬取下来的数据都是乱序的,有解,安装个东西就可以了。
电脑上安装 CouchDB,按照这个教程来就可以了。
有作业的,爬 100 条数据,http://kj.idcby.com/Gradingrel.aspx?mid=5&ID=190103030001,爬完之后,截图发微信群里打卡。
